8. Mapping and Monitoring Drought#
8.1. Summary#
Drought monitoring is critical for managing water resources, predicting agricultural productivity, and mitigating environmental impacts. Satellite-based data has emerged as a powerful tool for tracking precipitation patterns and assessing drought conditions in real-time. One widely used metric for this purpose is the Standardized Precipitation Index (SPI), which quantifies drought severity based on historical precipitation data. By leveraging satellite-based precipitation measures, we can generate the SPI and apply it to map and monitor drought on various spatial and temporal scales.
This notebook provides an introduction to the SPI, demonstrates how to compute it using satellite precipitation data, and explores its application in drought monitoring.
8.2. Learning Objectives#
8.2.1. Overall goals#
The primary objective of this notebook is to demonstrate the use of satellite-based precipitation data (e.g., CHIRPS) to calculate indices like the Standardized Precipitation Index (SPI), enabling the quantification and characterization of drought conditions based on the SPI in a given region or country.
8.2.2. Specific goals#
At the end of this notebook, you should have gained an understanding and appreciation of the following:
Understand the Standardized Precipitation Index (SPI):
Define SPI and explain its importance in drought assessment.
Describe how SPI is calculated and interpreted.
Explore Satellite-Based Precipitation Data:
Learn how to access and use satellite-based precipitation datasets.
Understand the advantages of satellite data for large-scale drought monitoring.
Compute and Visualize SPI:
Use satellite precipitation data to calculate SPI.
Visualize SPI maps and analyze drought conditions across different regions and timeframes.
Apply SPI for Drought Monitoring:
Identify drought trends and severity using the SPI.
Explore how SPI can inform decision-making in water resource management and agriculture.
8.3. Reference Materials#
The materials presented in this notebook is built on top of the amazing work that the World Bank Data Lab has previously done in the Morocco Economic Monitor Project. Please refer to the repository for more details but specifically, please check the following:
Overview of satellite based monitoring of drought. This section includes an explanation of the SPI as a drought index, along with examples from Morocco.
SPI generation guide. This section offers a guide on how to utilize satellite precipitation estimates, such as CHIRPS, to generate the Standardized Precipitation Index (SPI)
Characterise drought using SPI. This section explains how to develop meaningful metrics to characterize drought conditions using the Standardized Precipitation Index (SPI).
8.4. Python Environment Setup (Optional)#
8.4.1. Required Python packages#
In order to work and process precipitation and other geospatial data, we will need the following Python packages (All this assumes you have Python installed (e.g., through Anaconda)). matplotlib, gdal, nco, cdo, netcdf4, pandas, geopandas, xarray
8.4.2. Python virtual environment#
To make things neat and easy, we can just create an environment
source .venv-drought/bin/activate
pip install -U pip
pip install -r requirements-drought.txt
8.4.3. Notes on GDAL installation#
Note that although you can pip install gdal, you need to have GDAL package installed first. There are several ways to do it but I recommend using “conda” as follows: conda install -c conda-forge gdal
8.4.4. Package for climate indices#
The climate-indices python package enables the user to calculate SPI using any gridded netCDF dataset. You are required to install this using pip install climate-indices. However, there are certain specifications for input files that vary based on input type.
8.5. Rainfall/Precipitation Data#
8.5.1. About Rainfall Data#
SPI requires monthly rainfall data, and there are many source providing global high-resolution gridded monthly rainfall data:
In this notebook, we will work with the CHIRPS data.
8.5.2. Downloading CHIRPS data#
We will download CHIRPS monthly data in GeoTIFF format and prepare it as input for SPI calculation.
We will use either the wget or curl command to achieve this as below on the command line.
mkdir CHIRPS
cd CHIRPS
export URL='https://data.chc.ucsb.edu/products/CHIRPS-2.0/global_monthly/tifs/'; curl "$URL" | grep -E 'a href=' | perl -pe 's|.*href="(.*?)".*|\1|' | { while read -r f; do wget "$URL"/"$f"; done }
All CHIRPS monthly data is in GeoTIFF format from Jan 1981 to May 2023 (this is lot of data +-7GB zipped files, and become 27GB after extraction, please make sure you have bandwidth and unlimited data package). Paste and Enter below script in your Terminal.
Gunzip all the downloaded files in the command line as follows:
gunzip *.gz
8.6. 1.0 Generating SPI Index#
We can summarize the steps involved in generating SPI indexing using CHIRPS data as follows:
Prepare the input data. These are initial preprocessing steps such as extracting just the region you are working on for the data.
Calculate the SPI. Calculate the indices on the terminal
Review and update dimensions.
Visualize the SPI.
We will go through all of these steps in details in the following cells.
8.6.1. 1.1 Preparing input data#
8.6.1.1. General notes about units#
Precipitation unit must be written as
millimeters,milimeter,mm,inches,inchorin.Data dimension and order must be written as
lat,lon,time(Windows machine required this order) ortime,lat,lon(Works tested on Mac/Linux and Linux running on WSL).If your study area are big, it’s better to prepare all the data following this dimension order:
lat,lon,timeas all the data will force following this order during SPEI calculation by NCO module. Let say you only prepare the data as is (leaving the order tolat,lon,time), it also acceptable but it will required lot of memory to use re-ordering the dimension, and usually NCO couldn’t handle all the process and failed.
8.6.1.2. Clipping CHIRPS GeoTiffs to Area of interest (AOI)#
Given that the raster files downloaded from CHIRPS are global, we need to clip the GeoTiffs only to the extent that we need. For example, Morocco. For this, we just need to have the the shapefile of the AOI to use for clipping.
8.6.1.3. Convert GeoTiff to NetCDF#
In order to generate the SPI, we utulize the netCDF data format which we have mentioned before. The conversion between between geospatial data formats such as GeoTiff to NetCDF is not always easy. For this task, we will utilize the convert GeoTiff to NetCDF
8.7. Visualizing Standardized Precipitation Index#
Assumptions
Remove all areas where spi is blank
import seaborn as sns
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(25,6))
p.plot(kind='area', stacked=True, alpha = 0.7, color = hex_color_codes, ax=ax)
ax.set_xlabel('Time', fontsize=14)
ax.set_ylabel('Percentage Area by Class', fontsize = 14)
ax.legend(title='Classes')
fig.suptitle('SPI 6 Month Percentage Area by Month and Class', fontsize=16)
plt.legend(loc='upper center', bbox_to_anchor=(0.5, -0.1), fancybox=False, shadow=False, ncol=9, fontsize=14)
<matplotlib.legend.Legend at 0x189c119a860>
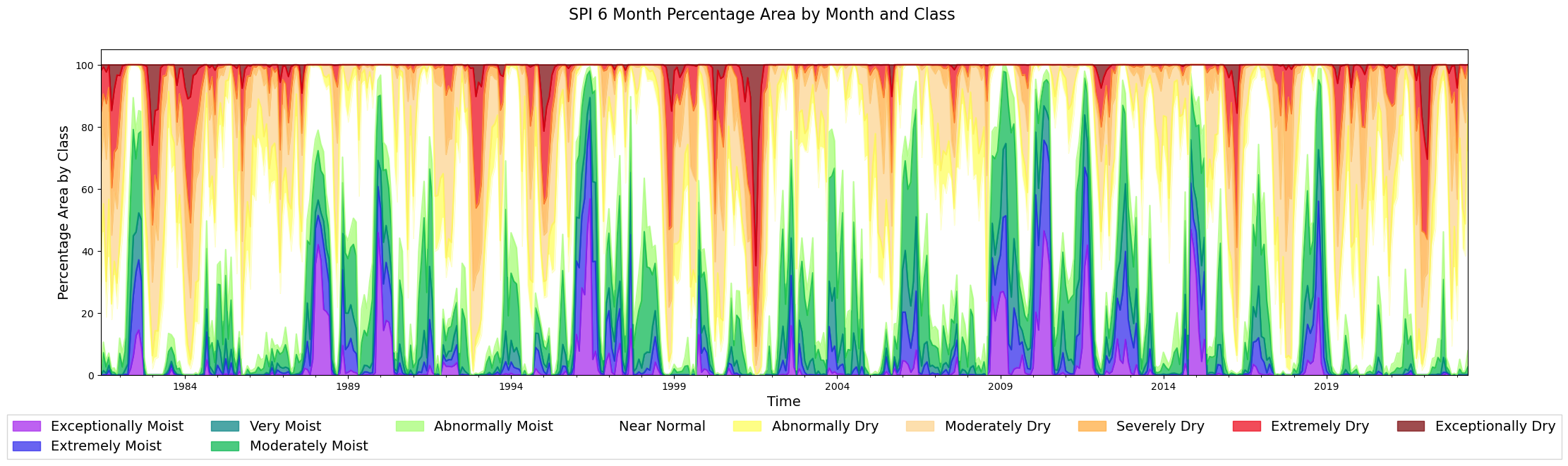
8.7.1. Observations#
The empty spaces are because of null values of SPI
2022, 2016, 2011-2002 were years of drought within Morocco
from matplotlib import rcParams
p = gdf_adm1[['adm1_name', 'time', 'percentage_area', 'class']]
rcParams['font.family'] = 'Georgia'
rcParams['font.sans-serif'] = ['Georgia']
fig, ax = plt.subplots(len(gdf_adm1['adm1_name'].unique()), 1, figsize=(25,70))
for i, adm in enumerate(gdf_adm1['adm1_name'].unique()):
p1 = p[p['adm1_name']==adm]
p1 = p1.reset_index().set_index('time')[['class', 'percentage_area']].pivot_table(columns ='class', values='percentage_area', index = 'time')
p1 = p1 [[
'Exceptionally Moist', 'Extremely Moist','Very Moist', 'Moderately Moist',
'Abnormally Moist', 'Near Normal', 'Abnormally Dry', 'Moderately Dry',
'Severely Dry', 'Extremely Dry', 'Exceptionally Dry']]
p1.plot(kind='area', stacked=True, alpha = 0.7, color = hex_color_codes, ax=ax[i], legend = False)
ax[i].set_xlabel('Time', fontsize=14)
ax[i].set_ylabel('Percentage Area by Class', fontsize=14)
#ax[i].legend(title='Categories')
ax[i].set_title(adm, fontsize=16)
plt.legend(loc='upper center', bbox_to_anchor=(0.5, 12), fancybox=False, shadow=False, ncol=9, fontsize=14)
<matplotlib.legend.Legend at 0x189c47f1d50>
8.8. Admin 1 regions in Dry Classes#
Dry Classes constitue of ‘Abnormally Dry’, ‘Extremely Dry’, ‘Severely Dry’, ‘Exceptionally Dry’
Text(0.5, 0.98, 'Maximum Percentage Area in SPI 6 month Drought Classes in a year by Adm1 Regions')
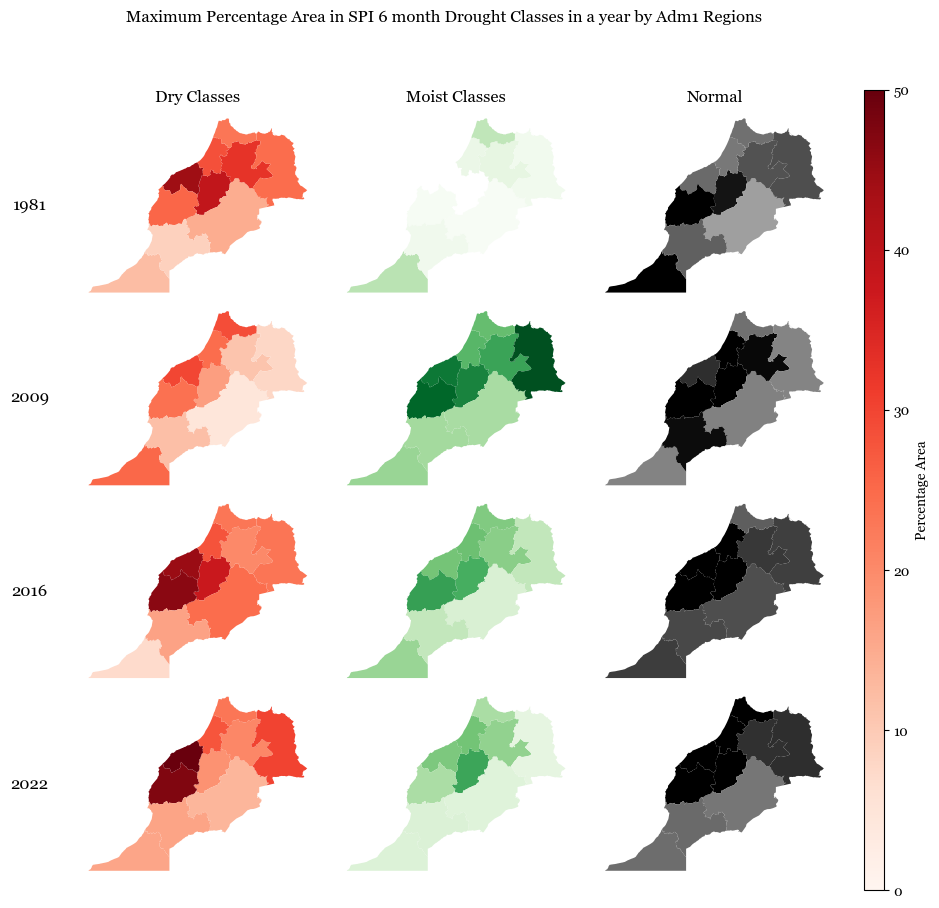
8.8.1. Observations#
The figure shows the maximum percentage area in each year that can be classified as dry, moist or normal based on the SPI classes i.e., it talks about the worst months of drought or rainfall.
2009 was one of the years which was reltively moist
2016 and 2022 were years with high dry conditions after 1981, as also validated by news outlets