Exploratory Data Analysis and Quality Assessment - Turkey#
1. Overview#
In this analysis, we conduct an Exploratory Data Analysis (EDA) and a Quality Assessment (QA) of large-scale mobility data collected in Türkiye in 2023. The EDA aims to characterize the structural properties of the dataset, including its temporal dynamics, spatial distribution, and patterns of user activity. Building on these explorations, the QA component evaluates data coverage, temporal stability, and representativeness, and identifies structural biases and limitations relevant to downstream analytical and policy-oriented applications. The analysis is conducted primarily at an aggregate level, to assess systematic features of the dataset rather than reconstruct individual mobility behavior.

1.1 Executive Summary#
The analyzed dataset contains approximately 1.12 billion GPS observations from 18.9 million users during 2023, with high overall temporal coverage (96.68%).
Overall assessment: The dataset is suitable for constructing aggregate, presence-based indicators of urban space usage, particularly in urban and peri-urban areas. However, its use requires explicit treatment of temporal regime shifts, uneven spatial coverage, and strong heterogeneity in user activity.
Key Findings#
1. Temporal dynamics are affected by changes in data capture intensity.
The dataset is stable for most of the year but exhibits three anomalous intervals: (i) a mid-year increase in tracking intensity per user, (ii) a sharp decline in active user coverage, and (iii) a year-end surge in total volume.
In addition, a 13-day data gap in September introduces a structural discontinuity. These shifts reflect changes in data generation rather than clear behavioral mobility changes and must be treated explicitly in longitudinal analysis.
2. Spatial coverage is highly uneven and concentrated in urban areas.
Mobility observations are strongly clustered in metropolitan regions and follow a heavy-tailed spatial distribution. A small fraction of spatial units accounts for a disproportionately large share of observations, while many rural and peripheral areas exhibit persistently low activity.
Population and activity alignment is substantially stronger in dense urban areas than in rural regions, indicating systematic underrepresentation of sparsely populated zones.
3. User activity is highly heterogeneous and daily traces are sparse.
User contributions follow a heavy-tailed pattern: a small subset of highly active users generates a large share of observations, while most users contribute limited and localized daily traces.
As a result, the dataset is structurally more robust as a presence signal than as a basis for detailed individual mobility reconstruction.
Implications for Policy Use#
Taken together, these findings indicate that the dataset should be interpreted primarily as a coverage and presence indicator, not as a complete representation of individual mobility behavior.
Accordingly:
Temporal comparisons require normalization. Raw time-series comparisons across different data regimes are not valid without adjusting for variations in user coverage and tracking intensity. We therefore recommend always applying normalization procedures, particularly when comparing distinct time periods, an approach that should generally be avoided unless strictly necessary.
Spatial aggregation is necessary outside urban cores. Fine-grained inference in low-activity areas is statistically unstable and should be avoided unless spatially aggregated or population-adjusted.
Individual-level mobility metrics require strong aggregation. Trajectory-based indicators are sensitive to user sparsity and contribution inequality and should not be used without filtering or normalization.
Overall, the dataset is well suited for aggregate, presence-based analyses of urban space usage at daily or coarser temporal resolution, particularly in urban and peri-urban areas. However, longitudinal analyses require particular caution: direct comparisons across time periods may reflect changes in sampling intensity or user coverage rather than real changes in mobility or space usage. Accordingly, analyses should:
(i) exclude or explicitly model anomalous periods, (ii) avoid comparing metrics across periods with different data capture regimes unless appropriately normalized, and (iii) avoid fine-grained inference in low-activity spatial units.
Importantly, the dataset does not support the construction of a full-year baseline of the Urban Space Usage Index, as regime shifts in tracking intensity and user coverage would introduce structural breaks unrelated to underlying spatial dynamics. A valid annual baseline must therefore be derived from temporally stable regimes or constructed using explicit normalization procedures to ensure interpretability and comparability over time.
2. Context and Objectives#
This analysis is conducted to generate high-frequency indices of urban space use (e.g., retail centers, construction sites, manufacturing zones, financial centers, residential areas). These indicators aim to inform policy-relevant analyses of urban activity, resilience, and responses to external shocks, including major events and climate-related disruptions.
The analysis focuses primarily on the spatial dimension of the data. Mobility observations generated by individuals are used to characterize aggregate patterns of activity across locations rather than to reconstruct individual mobility trajectories. Users are therefore treated as proxies for mobility intensity and the relative popularity of places, rather than as units of behavioral inference.
Accordingly, the EDA and QA prioritize the assessment of aggregate, presence-based spatial signals, with particular attention to coverage, temporal stability, and sensitivity to spatial and temporal aggregation choices. User-level trajectory analyses are explicitly outside the scope of this evaluation.
The findings of this assessment directly inform methodological decisions in subsequent project phases, including the selection of spatial resolution, normalization strategies, and temporal smoothing procedures used to construct the Urban Space Usage Index.
3. Dataset Overview#
The mobility dataset used in this analysis is the Veraset Movement dataset, provided by Veraset as part of the Mobility Data collection from the Development Data Partnership. This dataset consists of anonymized, high-frequency mobile device location pings collected through a network of mobile applications and software development kits (SDKs). Each record captures a device’s geographic coordinates (latitude and longitude), a UTC timestamp indicating when the observation was recorded, and a device identifier.
For this particular study, the analysis focuses on mobility patterns in Türkiye during the year 2023, using the dataset to examine spatial and temporal movement dynamics within the country.
3.1 Data Sources and Structure#
The dataset is collected and stored at a daily granularity and includes the following fields:
uid(string): Unique identifier of the userdatetime(datetime, UTC): Timestamp of the observation, recorded in UTChex_id(string): H3 spatial index at resolution 7latitude(float): Latitude coordinatelongitude(float): Longitude coordinatecountry(category): Country code
A preliminary check confirms that the country field is constant and equal to TR for all records, indicating that the dataset covers a single geographic area and that this variable does not contribute to analytical variability.
All timestamps are reported in UTC and must be converted to the appropriate local time zone before performing any time-based analysis. After conversion, records associated with a given partition date may shift to the previous or following local calendar day, depending on the time zone. In addition, a small subset of records may exhibit minor temporal offsets due to signal transmission delays. Furthermore, as specified in Veraset’s data documentation, the data feed may include observations from adjacent dates up to three days after the nominal delivery date. For example, events captured on January 1 (based on utc_timestamp) may appear in data feeds distributed between January 1 and January 4.
To properly account for both time zone conversion effects and feed delivery lags, it is therefore necessary to load data ranging from one day prior to up to three days after the target date to ensure that all relevant records are captured.
3.2 Dataset Statistics#
Metric |
Value |
|---|---|
Total GPS points |
1.12 billion |
Total users |
18.89 million |
Total active areas |
104,089 |
Time span |
Jan-Dec 2023 |
Missing days |
January 1st and September 18th 3 AM - 30th 3 AM |
Spatial unit |
H3 res 7 (lat/lng data; aggregable to any H3 resolution) |
Temporal coverage |
96.68% |
Spatial coverage |
67.92% |
Avg. points / day |
3,165,360 |
Avg. users / day |
212,060 |
Avg. hexes / day |
14,358 |
3.3 Dataset Temporal Coverage#
We assess the temporal coverage of the dataset relative to the 2023 calendar year. Overall temporal coverage is high, with observations available for 96.68% of all days and hours in 2023 (Figure 1).
Two explicit data gaps are identified. First, observations are missing on January 1st between 00:00 and 03:00, corresponding to the beginning of the year. Second, a continuous interruption in the data occurs from September 18th at 03:00 to September 30th at 03:00, amounting to a 13-day gap. Because September 18th and September 30th contain only partial observations (3 and 21 hours, respectively), both days are excluded to ensure consistency in daily aggregation. Consequently, the period September 18th to September 30th (inclusive) is treated as missing in the daily analysis. We recommend treating September 18–30 as structurally missing and avoiding interpolation across this interval in time-series analyses, as it introduces a discontinuity in the data-generating process.
Outside of these periods, the dataset contains observations for every day and hour of the year.
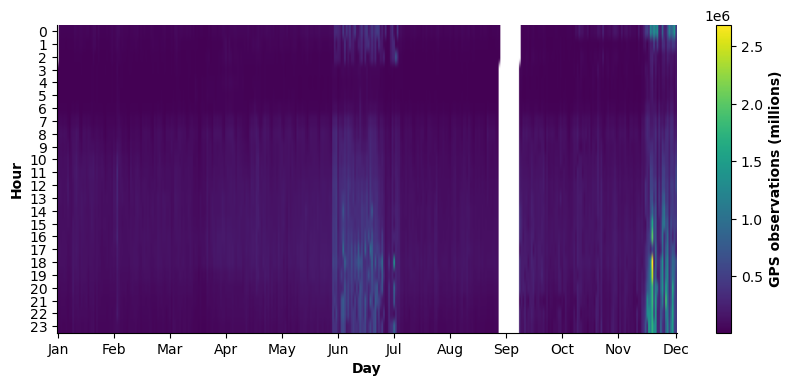
Figure 1. Heatmap showing the total number of GPS points recorded for each hour of the day across the calendar year. The colorbar represents the absolute number of GPS observations (in millions), with lighter shades indicating higher volumes. White areas indicate periods with no recorded observations.
3.4 Dataset Spatial Coverage#
The dataset provides nationwide coverage of Türkiye at the latitude-longitude level and is aggregated by default to H3 hexagons at resolution 7, corresponding to an average cell area of approximately 5 km². Due to the availability of latitude-longitude coordinates, data can be re‑aggregated to any spatial resolution.
Spatial coverage is defined as the share of H3 hexes covering the national territory that record at least one observation over the year. Under this definition, the spatial coverage of the dataset is 67.92%. As illustrated in Figure 2, hexes with no recorded observations are predominantly located in rural, mountainous, or sparsely populated areas, particularly in the eastern and central regions of the country.

Figure 2. Spatial coverage of H3 hexagons (resolution 7) in Türkiye, 2023. Hexagons that record at least one GPS observation during the year are shown in blue. Hexagons with no recorded observations are shown in orange. Spatial coverage is defined as the share of H3 hexagons with at least one observation over the study period.
4. Temporal Data Quality Assessment#
This section examines the temporal dimension of the mobility dataset by analyzing daily activity levels, intra-day (hourly) patterns, and differences between weekdays and weekends. The analysis focuses on the evolution over time of the number of observations, active users, and visited spatial units, as well as on circadian mobility rhythms reflected in hourly distributions. Taken together, these dimensions provide insight into the temporal stability and representativeness of the dataset and support the identification of temporal gaps, irregular sampling patterns, and structural changes in recording intensity that may affect downstream analyses.
4.1 Total Points, Unique Users, and Visited Hexes per Day#
Figure 3 presents the daily time series of the number of GPS observations, unique active users, and unique visited hexagons over the study period.
Baseline period
For most of the observation period, both the number of observations and visited hexes remain relatively stable, with coefficients of variation (CV) of 22% and 11.8%, respectively. In contrast, the number of unique users exhibits greater day-to-day variability, with a CV of 52.82% during this time. We define the baseline period as the joint intervals from the beginning of the year until June 10 and from October 1 through December 12. This baseline represents the standard data-generation regime and serves as the reference for comparing anomalous phases.
T1) Dense-User Tracking Period (11 June - 21 July)
A clear structural break emerges on 11 June and persists until 21 July. During this interval, the number of GPS observations increases sharply, and the number of visited hexes rises substantially relative to the baseline regime (+171% and +92%, respectively), while the number of unique users declines markedly (-30%).
This divergence indicates that the observed increase in recorded activity is unlikely to reflect an actual rise in mobility. Instead, it supports the hypothesis of denser tracking per user (e.g., higher sampling frequency or a change in app behavior), rather than a real change in mobility. As a result, we observe more points and spatial units for a smaller user base.
T2) User-Drop Period (21 July - mid-September)
Beginning on 21 July and lasting until the September data gap, the number of unique users collapses to extremely low levels compared to the baseline period (-97%, from 250,000 to 7,500) and remains structurally suppressed. This is not a moderate decrease but a strong reduction in user coverage. Although observations and hex counts remain consistent with baseline levels, they operate on a drastically reduced user base. Based on the plot, this period should be characterized as a structural breakdown of data coverage and not just a decline in activity. The data-generation process appears severely disrupted during this interval.
T3) Year-End Surge (13 December - 31 December)
A second structural shift arises from 13 December onward. During this interval, the number of observations increases sharply, reaching the highest levels observed during the year (+390% compared to the baseline). Unlike the dense-user tracking period, this increase is accompanied by a strong increase in the number of unique users and a moderate expansion in spatial coverage. This pattern suggests an overall expansion in data volume driven by both user growth and higher observation intensity. The magnitude and abruptness of the increase point to a platform-level change in the user base and tracking rather than routine seasonal mobility variation.
In conclusion, the time series analysis reveals that the first part of the year and the period from October to mid-December are stable and consistent. In contrast, the mid-year interval is characterized by a dense-user tracking period (T1), followed by a user-drop period (T2) and a data gap in September, and finally by a year-end surge (T3). These structural shifts reflect changes in data generation rather than clear mobility dynamics. Consequently, any longitudinal analysis covering the second half of the year should be conducted with caution, applying appropriate normalization or adjustments to account for variations in tracking intensity and user coverage.
Regime |
Main Signal |
Primary Driver |
Usability |
CV Points (%) |
CV Users (%) |
CV Hexes (%) |
|---|---|---|---|---|---|---|
Baseline |
Stable across metrics |
Normal data regime |
High |
22.11 |
52.82 |
11.82 |
T1 |
More points, fewer users |
Higher tracking intensity |
Medium (needs normalization) |
31.45 |
58.60 |
15.44 |
T2 |
Collapse in users |
Coverage breakdown |
Low |
20.17 |
13.74 |
11.64 |
T3 |
Surge in all metrics |
Platform-level expansion |
Medium (structural shift) |
37.10 |
9.93 |
3.35 |
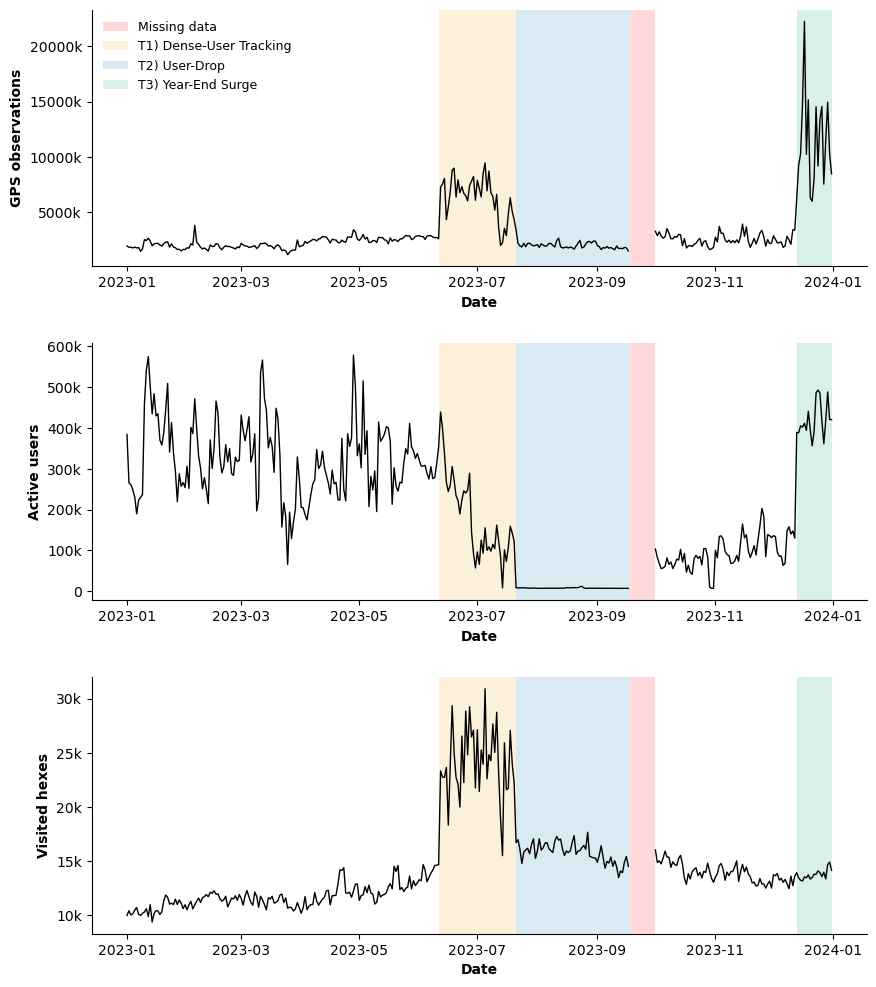
Figure 3. Daily time series of total GPS observations (top), number of unique active users (middle), and number of visited spatial units at H3 resolution 7 (bottom). Shaded regions indicate data regimes: baseline period (white), Dense-User Tracking Period (T1; orange), User-Drop Period (T2; blue), missing data interval (red), and Year-End Surge (T3; green).
Relationships among Total GPS Points, Unique Users, and Unique Visited Hexes#
To evaluate how the relationships among total GPS points, unique users, and unique visited hexes change over time, we compare their daily correlations across the identified “outlier” periods T1, T2, T3, and the baseline period (see Figure 4). This comparison helps determine whether observed changes in data volume reflect true mobility dynamics or simply variation in data collection intensity.
During the baseline period (black points), the three indicators follow a compact and consistent scaling structure that serves as the reference regime. GPS observations increase with visited hexagons. However, increases in the number of users do not systematically translate into broader spatial coverage, suggesting that additional users largely overlap in already active areas rather than expanding the spatial footprint.
In the Dense-User Tracking Period (T1) (orange points), the number of GPS observations is substantially higher than in the baseline regime, and spatial coverage expands disproportionately. At the same time, the user base declines. This pattern indicates higher observation intensity per user, consistent with denser tracking or increased sampling frequency rather than an actual increase in mobility.
During the User-Drop Period (blue points), the number of unique users collapses, while observations and visited hexagons persist but are generated by a much smaller participant base. This phase reflects a structural breakdown in user coverage instead of a gradual decline in activity.
The Year-End Surge (green points), unlike the dense-user tracking period, is characterized by simultaneous increases in users and observations, while spatial coverage remains broadly stable. This configuration suggests an overall expansion in data volume driven by a higher number of points associated with each user.
This finding highlights temporal inconsistencies in data collection and underscores that longitudinal analyses spanning these periods should apply appropriate normalization or regime-specific adjustments to ensure comparability.
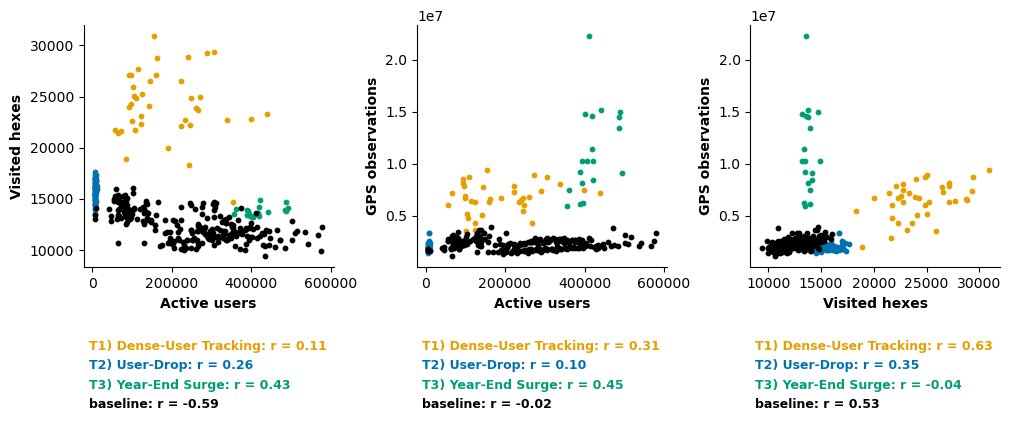
Figure 4. Scatter plots illustrating the daily relationships among total GPS observations, number of unique users, and number of visited hexagons. Points are color-coded by regime (baseline, T1, T2, T3) to highlight differences in scaling patterns across periods.
4.2 Circadian Rhythm: Hour-of-day Distributions#
The hour‑of‑day distributions of points, active users, and active spatial hexes exhibit a circadian pattern, as shown in Figure 5. As expected, activity is lowest during nighttime hours, followed by an increase in the early morning, a sustained plateau from late morning through early evening, and a gradual decline thereafter. In addition, two local peaks are visible, corresponding to the morning and evening periods, a well-known feature of human mobility patterns. The consistency of these circadian profiles across indicators provides an important quality check, suggesting that despite temporal fluctuations in data volume, the dataset preserves realistic daily mobility rhythms [JYG+16].
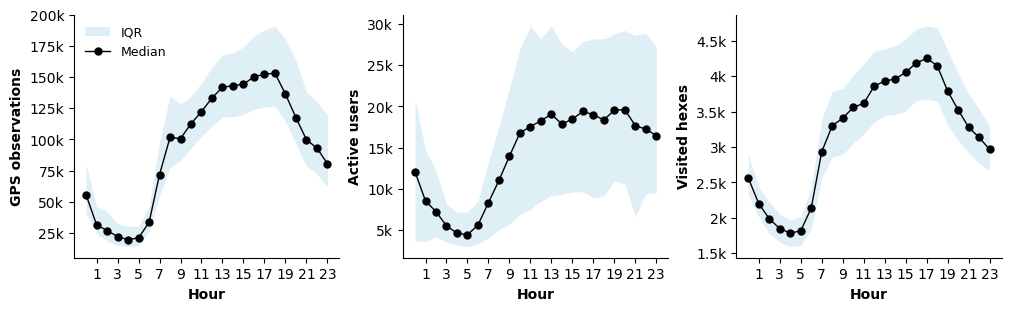
Figure 5. Average hourly distribution of total GPS observations, unique users, and active hexagons across all available days in 2023 (local time). Values are aggregated across the full observation period.
4.3 Weekend vs. Weekday#
We also investigate how mobility and activity patterns differ between weekdays and weekends (Figure 6). During weekends, activity tends to start later in the morning, while the early-morning peak observed on weekdays is attenuated. Conversely, weekend activity exhibits a more pronounced increase during the afternoon and early evening.
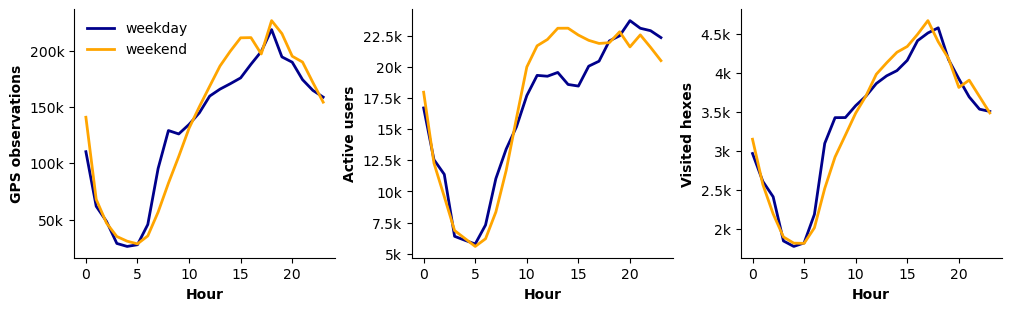
Figure 6. Comparison of mean hourly GPS observations between weekdays and weekends, aggregated over the study period. Curves reflect differences in intra-day activity profiles.
We further examined whether the weekday-weekend differences, which exhibit distinct intra-day circadian patterns, also translate into differences in the total number of observations within the same week. To assess this, we compared, for each week, the total number of observations recorded on weekdays versus weekends and computed the relative percentage difference. The results indicate that the number of observations during weekdays tends to be slightly higher than during weekends, with an average increase of 4-6%. However, this difference is not statistically significant when evaluated across weeks (Wilcoxon p ≈ 0.07; t-test p ≈ 0.11).
4.4 Data Quality Implications#
Temporal patterns in user counts, observation volumes, and spatial coverage reveal several important data quality considerations, particularly during the T1 interval (i.e., the Dense-User Tracking Period). Under stable sampling conditions, a true increase in mobility would be expected to coincide with stable or rising numbers of active users. The observed combination of declining user counts alongside increasing numbers of observations and visited hexes instead points to changes in tracking intensity or data ingestion processes, rather than to substantive behavioral shifts. As a result, absolute activity levels observed during peak periods are not directly comparable to those recorded during non-peak intervals.
Following the outlier interval T1, the number of users remains low until the September data gap, further limiting the reliability of user-based indicators during this period. Temporal comparisons spanning this phase should be avoided unless explicit adjustments are applied. We recommend treating September 18–30 as structurally missing and avoiding interpolation across this period, as it introduces a discontinuity in the data-generating process that may bias longitudinal comparisons.
The circadian and weekday vs. weekend patterns follow well‑established mobility rhythms, including morning and evening peaks. While this consistency supports the internal validity of the data, it also implies that comparisons across hours, days, or day types must be interpreted cautiously, as observed differences may reflect structural temporal rhythms rather than behavioral change.
For a robust temporal analysis, comparisons should be restricted to homogeneous temporal regimes (e.g., within the same outlier interval or stable-to-stable periods). Indicators should be normalized, and the September data gap should be explicitly excluded or adjusted. If these conditions are met, temporal patterns are stable and interpretable. In summary, longitudinal analyses should either exclude anomalous periods or rely on normalized metrics, such as adjustments by active-user counts, to ensure comparability and reduce sensitivity to variations in user coverage and tracking intensity, especially when comparing different time periods.
5. Spatial Data Quality Assessment#
This section examines the spatial dimension of the mobility dataset by analyzing spatial coverage, concentration, and sparsity across H3 hexagonal units. The analysis focuses on the distribution of observations and users across space, the degree of spatial inequality, and the relationship between observed users and resident population.
Our analysis provides insight into the spatial representativeness and reliability of the data and support the identification of uneven coverage, highly concentrated activity patterns, and low-activity spatial units that may affect downstream spatial analyses and indicator construction.
5.1 Spatial Distribution#
The map in Figure 7 illustrates the spatial distribution of mobility observations collected in 2023 across Türkiye, aggregated on an H3 hexagonal grid (resolution 7, ≈ 5.161 km² per hex) and expressed as the average number of points per hex during 2023.
As expected, observations are strongly concentrated around major urban centers, including Istanbul, Ankara, Izmir, and other metropolitan areas. This spatial pattern reflects higher population density and activity levels in urban environments. In contrast, rural and sparsely populated regions exhibit lower observation volumes, consistent with demographic distributions.
A non‑negligible number of observations are detected over water bodies, particularly in coastal areas such as the sea in front of Istanbul. These observations are plausibly explained by individuals carrying GPS‑enabled devices while traveling by ferry, boat, or ship. A further notable feature is the presence of a distinct linear structure in the eastern part of the map. This straight‑line pattern does not correspond to known road infrastructure and is therefore unlikely to reflect ground transportation. A plausible interpretation is that these observations were recorded along an air travel corridor, where GPS positions are intermittently logged during flights. Such artifacts should be explicitly accounted for or filtered in downstream spatial analyses.
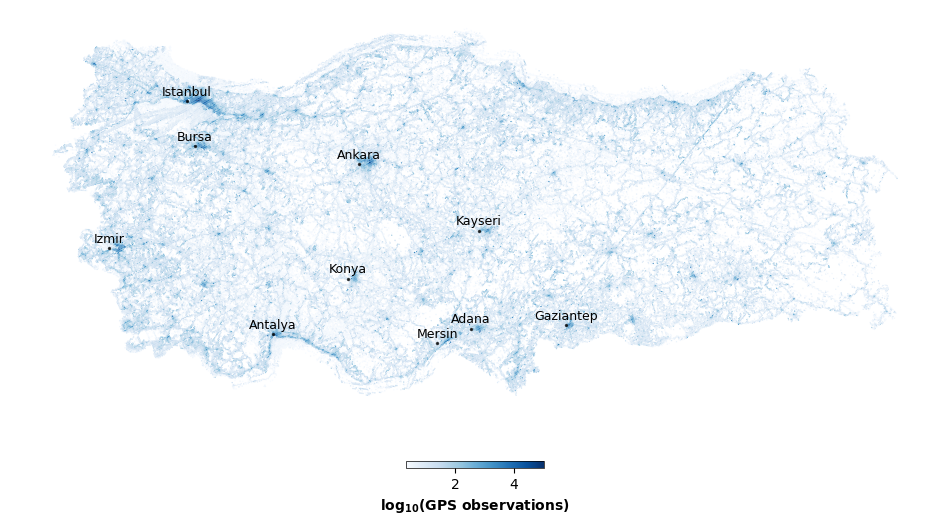
Figure 7. Spatial distribution of GPS observations shown as the average annual number of records per H3 hexagon (resolution 7). Higher values represent a greater concentration of recorded activity. The color scale is log₁₀-transformed, with darker blue tones indicating areas with more observations.
5.2 Total Points and Unique Users per Visited Spatial Unit#
Each spatial unit corresponds to an H3 hexagon at resolution 7 (see the figure below for an illustrative example). Overall, daily activity at the hex level is typically low. On average, each spatial unit (i.e., a hex or hexagon) contains approximately 220 points generated by 20 users. However, these values decrease substantially when considering the median: in the median case, a hexagon contains 15 points generated by 2 users. The average number of users per hexagon is 20.44. The pronounced gap between the mean and the median reflects a strongly right-skewed spatial distribution.
The time series of points- and users‑per‑hex metrics (Figure 8, left and right, respectively) remain broadly stable over the year. During the Dense-User Tracking Period (T1), most visible in the upper quantiles, there is increased spatial concentration of activity, whereby fewer users are tracked more intensively within a limited subset of locations. Outside of this period, no major structural changes in spatial intensity are observed.
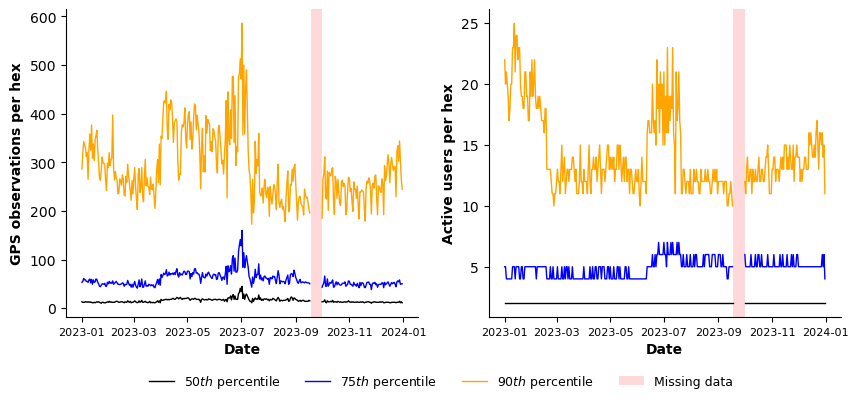
Figure 8. Daily values of points per hexagon (left) and users per hexagon (right). The black line represents the 50th percentile (median), the blue line the 75th percentile, and the orange line the 90th percentile. The shaded area indicates periods of missing data.
5.3 Inequality of Distribution of Observations across Spatial Units#
We analyze the distribution of observations across spatial units (H3 hexes) to assess the degree of spatial inequality, as most hexes receive very few observations, while a small fraction concentrates a disproportionately large share of GPS points.
This inequality is evident in both the rank-size distribution (Figure 9, left), which displays a heavy‑tailed behavior, and in the Lorenz curve (Figure 9, right), having an associated Gini coefficient of 0.85, indicating spatial concentration of activity within a small number of hexes. This level of inequality is expected in human mobility data, where visit frequencies are well known to follow power‑law or heavy‑tailed distributions. Empirical studies based on large‑scale GPS and mobile phone data consistently show that most locations are visited infrequently, while a small number of highly attractive locations accumulate the majority of visits [GHB08, BBG+18].
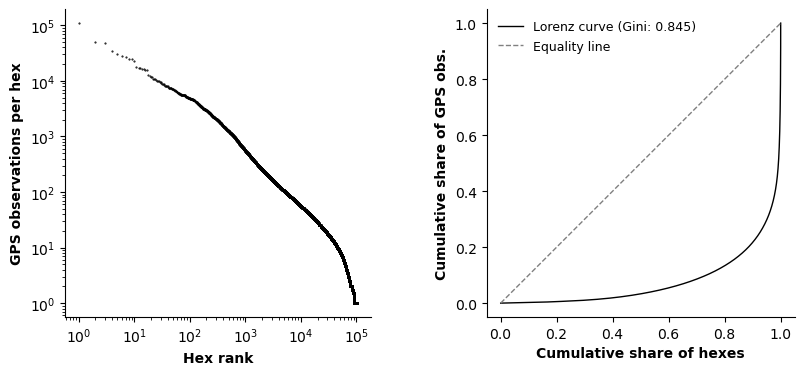
Figure 9. Rank-size distribution of total GPS observations per H3 hexagon, illustrating a pronounced heavy-tailed distribution (left). Lorenz curve showing the cumulative share of observations by ranked hexagons (right), with the corresponding Gini coefficient (0.85) quantifying the high degree of spatial inequality in activity concentration.
We further characterize spatial inequality by examining the share of total observations captured by the most frequently visited hexes. The results shown in Figure 10 highlights that the top 1% of hexes consistently account for about 40% of all GPS points, highlighting an extreme concentration of activity. Expanding to the top 2% and 5% of hexes substantially increases the cumulative share, confirming that overall visitation is dominated by a very small fraction of locations.
This concentration pattern is stable over time, with only moderate fluctuations that mirror previously identified temporal dynamics in data capture. The persistence of these shares indicates that spatial inequality is a structural property of the dataset, rather than the result of short-term shocks or transient changes in mobility behavior.
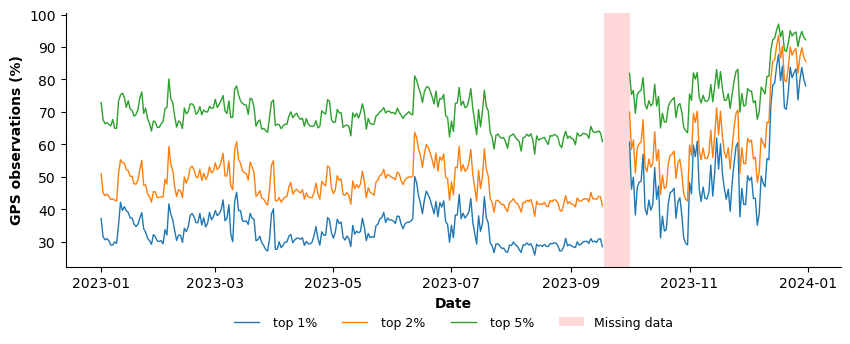
Figure 10. Time series of the share of total GPS observations captured by the highest-ranked H3 hexagons at different thresholds: top 1% (blue), top 2% (orange), and top 5% (green) most visited hexagons.
5.4 Spatial Representativeness#
GPS observations are collected through GPS-enabled devices and therefore represent only a subset of the total population within the study area. Specifically, they capture individuals who own smartphones, have specific applications installed, and have enabled location-sharing permissions accessible to the data provider. Consequently, the derived mobility metrics should not be interpreted as measures of the true total population. Rather, they serve as high-frequency proxies for the spatial and temporal distribution of observed device users.
To assess spatial representativeness and identify potential representation bias, we examine the relationship between the resident population and observed users at the H3 hexagon level. Specifically, we correlate the average daily number of unique users per hexagon with the corresponding resident population counts (data extracted from WorldPop). At the aggregate level, population and observed users exhibit a moderate positive association (Figure 11; Pearson’s r ≈ 0.48), suggesting that more populous areas tend to register higher numbers of observed users, albeit with substantial spatial variability.
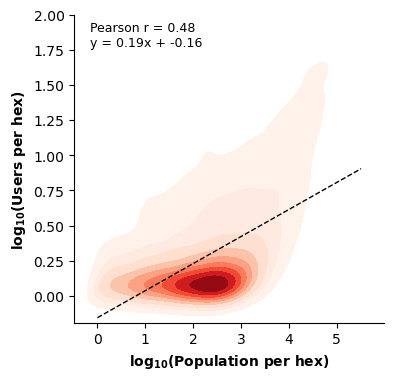
Figure 11. Bivariate kernel density plot of resident population estimates (WorldPop) versus the average daily number of unique users per H3 hexagon (Pearson correlation, r ≈ 0.48). The dashed line represents the linear fit. Red color intensity corresponds to higher point density.
Population-Mobility Scaling by Urbanization Level#
To better characterize heterogeneity in the population-mobility relationship, we stratify H3 hexagons by level of urbanization using population‑based quantiles (Figure 12), with thresholds chosen as analytical assumptions. Specifically, hexes are classified as:
Rural hexagons: bottom 40% of the population distribution, representing low‑density areas.
Suburban (peri‑urban) hexagons: middle 40%, capturing transitional zones between rural and urban areas.
Urban hexagons: top 20%, characterized by high population density
For each class, we compute Pearson correlation coefficients (see Figure 13). From our analysis, differences emerge across urbanization levels. In rural and suburban hexes, correlations are weak and scaling exponents are close to zero, indicating a limited coupling between resident population and observed users. In contrast, urban hexes exhibit a strong positive association (r ≈ 0.72) and a clear scaling relationship, reflecting a more systematic alignment between population density and user presence in urban environments.
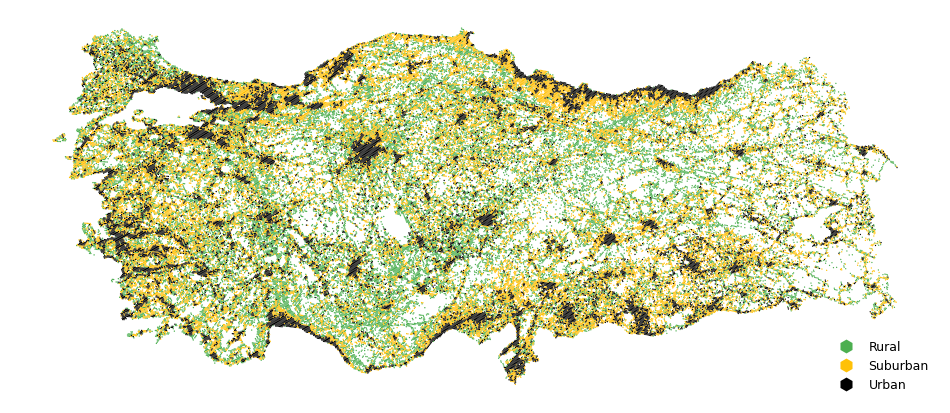
Figure 12. Spatial classification of H3 hexagons into rural (green), suburban (yellow), and urban (black) categories across the study area. The map highlights the extensive coverage of rural hexagons, with suburban areas forming transition zones around major urban centers, and urban hexagons concentrated in densely populated metropolitan regions.
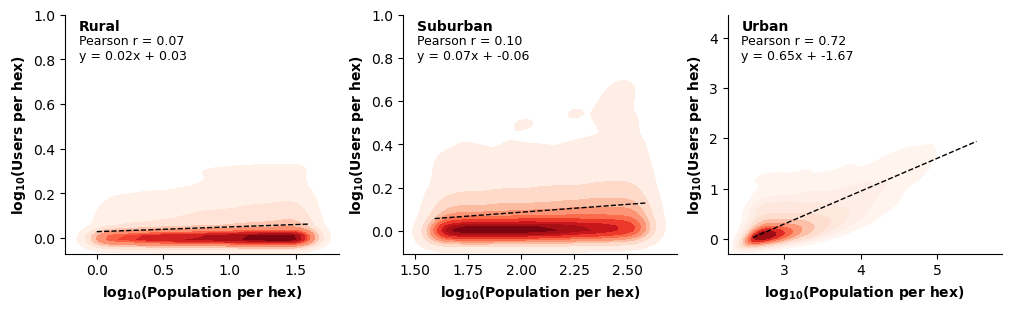
Figure 13. Bivariate kernel density plots and fitted linear relationships between resident population and observed users for rural, suburban, and urban H3 hexagons (defined by population quantiles).
5.5 Effects of User and Point Thresholds on Spatial Units#
Only a limited share of hexes exhibits very low daily activity. As Figure 14 shows, on average, approximately 6.9% of hexes record at most one point per day, increasing to 14.0% for ≤2 points and 27.5% for ≤5 points.
Number of Points per Hex |
Share of Hexes (%) |
|---|---|
≤ 1 |
6.91 ± 2.19 |
≤ 2 |
14.02 ± 2.39 |
≤ 5 |
27.46 ± 4.52 |
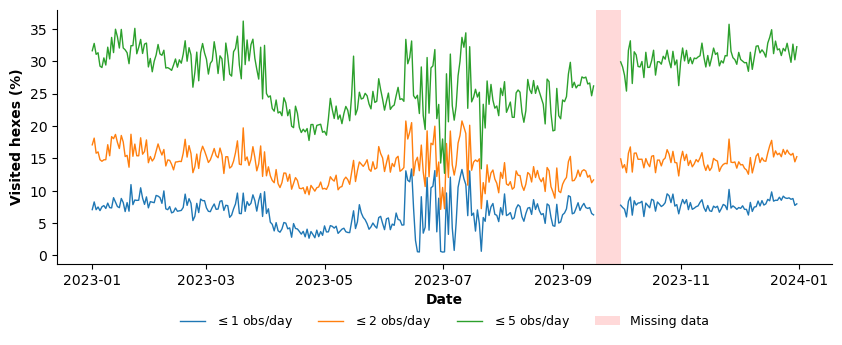
Figure 14. Time series of the share of H3 hexagons recording ≤1 (blue), ≤2 (orange), and ≤5 (green) GPS points. The figure illustrates the proportion of low-activity hexagons over time.
In addition, a substantial fraction of hexes is visited by very few unique users (Figure 15). On average, approximately 41.5% of hexes record visits from at most one user per day, increasing to 58% for ≤2 users and 67.1% for ≤3 users. This indicates that many spatial units are characterized by highly localized or sporadic usage, often driven by a very small number of individuals rather than by broad user participation.
Number of Users per Hex |
Share of Hexes (%) |
|---|---|
≤ 1 |
41.45 ± 2.82 |
≤ 2 |
58.00 ± 3.16 |
≤ 3 |
67.14 ± 3.04 |
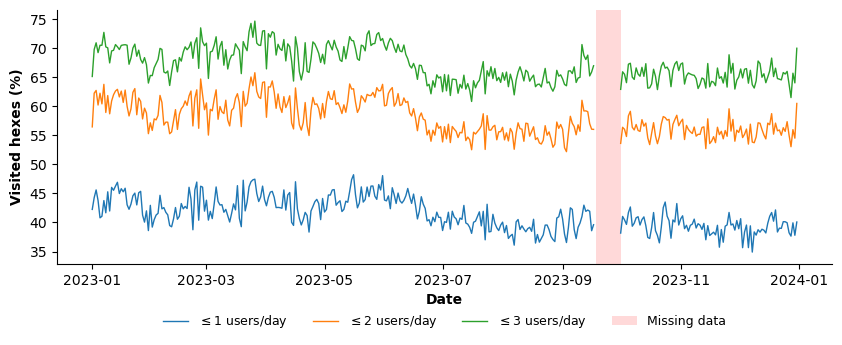
Figure 15. Time series of the share of H3 hexagons visited by ≤1 (blue), ≤2 (orange), and ≤5 (green) unique users.
5.6 Data Quality Implications#
The spatial distribution of observations is consistent with known mobility patterns, with spatial activity concentrated in metropolitan areas. This alignment supports the dataset’s spatial reliability. The presence of observations over water bodies and along linear trajectories indicates that raw spatial traces include movement-related artifacts (e.g., ferry routes or air travel). Depending on the analytical objective, these artifacts can be explicitly filtered, as they do not represent stationary activity at those locations.
The distribution of visits across hexes is highly skewed, with a small number of locations accounting for a large share of total activity. This heavy-tailed structure is a well-established mobility feature and should be interpreted as a realism check rather than a data-quality issue. However, it has important analytical implications: simple averages are dominated by high-activity hexes, and distribution-aware metrics (such as medians, quantiles, or inequality measures) are more appropriate for spatial characterization.
Spatial representativeness varies systematically with urbanization level. Coverage is strongest in dense urban areas and substantially weaker in low-density rural regions. Analyses at H3 resolution 7 (or higher) are reliable primarily in urban cores; in rural and peripheral areas, spatial aggregation (e.g., resolution 6 or higher-level administrative units) is required to obtain stable, interpretable signals.
6. User Activity Assessment#
This section examines the user-level dimension of the dataset by analyzing patterns of activity, spatial behavior, and contribution inequality across individuals. Specifically, we investigate the distribution of observations per user, the prevalence of sparse daily traces, and the extent to which user activity is spatially localized.
Given that our primary objective is to construct an Urban Space Index, we do not focus on individual mobility descriptors such as radius of gyration, nor do we attempt to characterize users’ mobility through detailed trajectory reconstruction. Instead, our analysis emphasizes aggregated behavioral patterns that are directly relevant to the proposed index.
6.1 Total Points, Visited Hexes, and Active Window per User#
User-level activity exhibits strong heterogeneity, as evident in Figure 16. The median user records approximately 3 GPS points, 1 visited location, and 208 minutes of observed activity per day, while mean values are substantially higher: 61 GPS points, 3 locations, and 300 minutes. This pronounced gap between the median and the mean implies a right-skewed distribution, in which a small share of highly active users accounts for most of the observations. In contrast, the majority of users generate sparse, discontinuous daily traces.
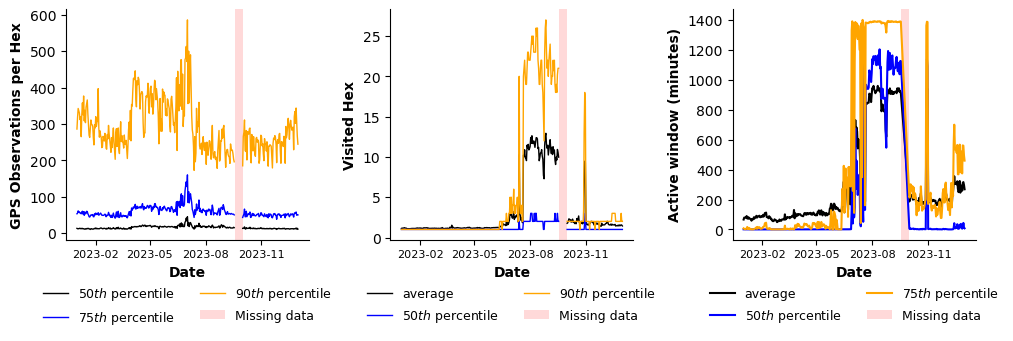
Figure 16. Daily values of GPS points per H3 hexagon (left), number of visited hexagons (middle), and active window in minutes (right). Lines represent selected quantiles (50th, 75th, and 90th percentiles as indicated) and the mean where shown. The shaded area denotes periods of missing data.
6.2 Inequality of Distribution of Observations across Users#
We assess user‑level contribution patterns to evaluate the degree of user‑representation inequality in the dataset. The distribution of GPS observations across users is highly uneven: most users contribute relatively few observations, while a small fraction of highly active users accounts for a disproportionate share of all recorded points.
This imbalance is clearly visible in the rank-size distribution, which exhibits a pronounced heavy-tailed shape, indicating differences between low- and high-contributing users (Figure 17, left). Consistently, the Lorenz curve diverges from the equity line, with an associated Gini coefficient of 0.583, highligting strong concentration of observations among a small share of users (Figure 17, right).
From a data quality perspective, this pattern is typical of passively collected mobility data. However, it has important analytical implications, particularly for user‑weighted metrics and for any analysis that relies on individual‑level mobility intensity.
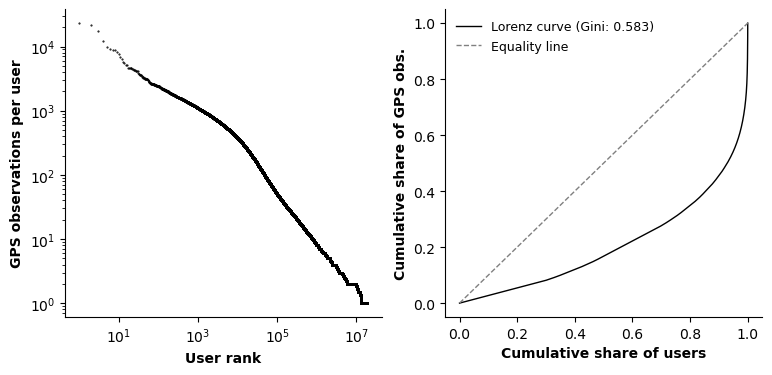
Figure 17. Rank–size distribution of total GPS observations per user, showing a pronounced heavy-tailed distribution in individual activity levels (left). Lorenz curve depicting the cumulative share of GPS observations by ranked users (right), with the corresponding Gini coefficient (0.583) quantifying inequality in user-level contribution to total activity.
6.3 Effects of Point and Hexes Thresholds on Users#
A vast majority of users exhibit very sparse daily activity (Figure 18). On an average day, approximately 28% of users generate at most one GPS point, nearly 50% record two or fewer points, and about 57% record three or fewer points. This share increases to 74% when considering users with ten or fewer daily points.
These figures indicate that most users contribute only limited and intermittent daily traces. Consequently, the dataset is not suitable for trajectory-level analyses of individual mobility. Any attempt to restrict the sample to “high-quality” users with sufficiently dense trajectories would require applying strict filtering criteria, which would substantially reduce the number of retained users and potentially introduce selection bias.
Number of Points per User |
Share of Users (%) |
|---|---|
≤ 1 |
28.42 ± 19.32 |
≤ 2 |
49.58 ± 29.36 |
≤ 3 |
56.54 ± 29.85 |
≤ 5 |
65.48 ± 29.43 |
≤ 10 |
73.81 ± 28.02 |
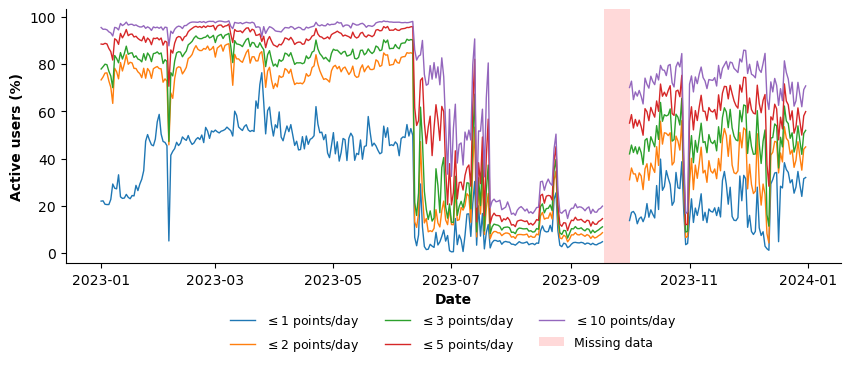
Figure 18. Daily percentage of users generating ≤1 (blue), ≤2 (orange), ≤3 (green), ≤5 (red), or ≤10 (purple) GPS observations. The shaded area denotes periods of missing data.
Most users are also spatially localized on a given day. On average, 81% of users visit at most one hex, and 88% visit two or fewer hexes. This pattern indicates that most daily activity reflects presence in a single location or a simple out-and-back pattern, rather than more complete trajectories. From a QA perspective, this behavior implies that user-level mobility metrics are likely to be data-sparse unless substantial temporal or spatial aggregation is applied, or minimum-activity thresholds are enforced (Figure 19).
Number of Hexes per User |
Share of Users (%) |
|---|---|
≤ 1 |
80.73 ± 20.04 |
≤ 2 |
88.46 ± 16.85 |
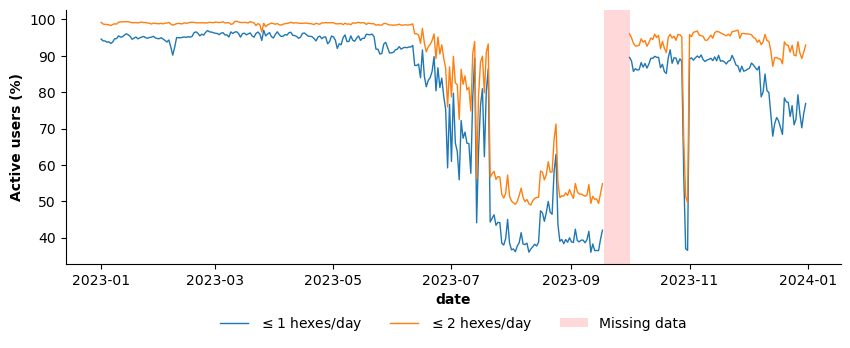
Figure 19. Daily percentage of users visiting ≤1 (blue) or ≤2 (orange) unique H3 hexagons. The shaded area denotes periods of missing data.
6.4 Data Quality Implications#
User contributions follow a heavy-tailed distribution, meaning that averages are often dominated by a small subset of highly active users, while the behavior of low-activity users is under-represented. Where user-level comparability is required, analyses should rely on distribution-aware summaries (e.g., medians or quantiles) and stratify results by user activity level.
A large share of users generates sparse daily traces. In this dataset, about 50% of users record two or fewer points per day (and about 57% record three or fewer). As a result, the data are well-suited to analyses that interpret user presence as a signal of mobility or exposure within an area. In contrast, user-centric analyses requiring individual trajectories risk excluding a large fraction of low-active users.
On a given day, most users also exhibit highly localized spatial behavior. On average, approximately 81% of users visit at most one hex, and around 88% visit no more than two hexes. This pattern suggests that daily observations typically capture presence in a single location or a simple out-and-back movement, rather than complex multi-stop trajectories.
From a quality-assurance perspective, these characteristics are consistent with expectations for passively collected mobility data and support analyses based on user presence or relative intensity within areas. In summary, user presence provides a reliable coverage signal, whereas individual mobility metrics are not robust without substantial aggregation.
7. Data Quality Assessment Summary#
This assessment evaluated the temporal, spatial, and user-level properties of the mobility dataset to determine its suitability for constructing an Urban Space Usage Index.
Overall, the dataset provides broad coverage and internally consistent aggregate signals. At the same time, it exhibits structural unevenness across time, space, and users that directly affects how indicators should be constructed and interpreted.
7.1 Temporal Dimension#
The dataset achieves high temporal coverage (96.68%) over 2023. Outside of three identified anomalous intervals and a 13-day interruption in September, daily patterns of observations and visited spatial units remain broadly stable, while the number of active users exhibits greater day-to-day variability.
However, pronounced regime shifts reflect changes in tracking intensity and user coverage rather than clear behavioral mobility changes. These structural breaks limit direct longitudinal comparability. Raw time-series comparisons across different regimes are not valid without normalization.
For index construction, temporally stable regimes should be identified and treated consistently, and anomalous intervals should either be excluded or explicitly modeled.
7.2 Spatial Dimension#
Spatial coverage is extensive (67.92%) but highly uneven. Activity is strongly concentrated in urban areas and follows a heavy-tailed distribution, with a small fraction of spatial units accounting for a disproportionate share of total observations.
Coverage is substantially weaker in rural and sparsely populated regions, where many spatial units exhibit persistently low activity. As a result, fine-grained spatial inference at high H3 resolutions is reliable primarily in dense urban cores. Spatial aggregation or population-aware normalization is required to ensure comparability outside these areas.
These characteristics are consistent with expectations for passively collected mobility data and do not invalidate the dataset, but they impose clear constraints on spatial resolution choices.
7.3 User Dimension#
User contributions are highly heterogeneous. A small subset of highly active users accounts for a large share of observations, while most users produce sparse, localized daily traces: 50% generate 2 or fewer points per day.
This structure limits the robustness of individual-level mobility metrics and trajectory-based indicators without substantial aggregation or filtering. In contrast, aggregate presence-based measures at the spatial-unit level are considerably more stable and appropriate for index construction.
7.4 Overall Assessment#
The dataset is suitable for constructing an Urban Space Usage Index when interpreted as a signal of relative presence and activity rather than as a comprehensive representation of individual mobility behavior.
Its principal strengths include large-scale coverage and stable aggregate dynamics within identified regimes. Its primary limitations arise from time-varying sampling intensity, uneven spatial representation, and user-level sparsity.
Accordingly, index construction should:
Rely on temporally stable regimes or apply normalization across regimes;
Apply spatial aggregation or population-aware adjustments in low-activity areas;
Avoid reliance on individual-level trajectory metrics;
Treat any annual baseline with caution, ensuring that structural regime shifts are explicitly accounted for.
When these safeguards are implemented, the dataset provides a reliable foundation for high-frequency monitoring of urban space usage.
Suitable and Non-Suitable Applications#
Suitable Applications
The dataset is well-suited for:
Aggregate, presence-based indicators of urban space usage
Relative comparisons across locations within similar coverage regimes
Urban and peri-urban analyses at daily or coarser temporal resolution
Event- or shock-related analyses, provided anomalous periods are explicitly handled
Non-Suitable Applications
Without substantial aggregation or correction, the dataset is not well-suited for:
Individual-level mobility profiling or behavioral inference
Fine-grained trajectory reconstruction or detailed OD analysis
Rural mobility indicators
Longitudinal comparisons that assume stable sampling intensity over time
DO |
DON’T |
|---|---|
Aggregate and smooth temporally (for example, weekly or monthly aggregation; rolling averages) and analyze within homogeneous data regimes (baseline versus T1, T2, T3). |
Do not attribute peaks or drops as real mobility effects before verifying that they are not driven by tracking intensity, ingestion changes, or missing data periods. |
Interpret temporal trends jointly with diagnostic indicators (active users, points per user, users per hex, regime flags) and explicitly document excluded or adjusted periods. |
Do not attribute daily or short-term fluctuations to behavioral change without normalizing for coverage variation and verifying regime stability. |
Use presence-based or relative metrics (for example, active users per hex, share of total activity, standardized change relative to a local baseline) to improve comparability. |
Do not treat raw point counts as measures of mobility volume or as direct proxies for total population activity. |
Correct for uneven spatial coverage through population-aware normalization, stratification by urbanization level, or reporting per-capita or per-device rates. |
Do not compare raw mobility levels across regions, particularly between urban and rural areas, without adjusting for sampling intensity and coverage differences. |
Match spatial resolution to data density by applying finer H3 levels only where user density is sufficient and aggregating rural or peripheral areas to coarser spatial units when necessary. |
Do not conduct fine-grained spatial inference in cells where daily activity is extremely low (for example, one or fewer users), as results will be statistically unstable and outlier-driven. |
For trajectory- or origin-destination-based analyses, enforce minimum data sufficiency thresholds (for example, minimum number of points per day or minimum active window) and report sensitivity to threshold choices. |
Do not compute individual-level mobility or origin-destination metrics on sparse traces, and do not apply aggressive filtering without explicitly assessing potential selection bias. |
8. References#
- 1
Shan Jiang, Yingxiang Yang, Siddharth Gupta, Daniele Veneziano, Shounak Athavale, and Marta C González. The timegeo modeling framework for urban mobility without travel surveys. Proceedings of the National Academy of Sciences, 113(37):E5370–E5378, 2016.
- 2
Marta C Gonzalez, Cesar A Hidalgo, and Albert-Laszlo Barabasi. Understanding individual human mobility patterns. nature, 453(7196):779–782, 2008.
- 3
Hugo Barbosa, Marc Barthelemy, Gourab Ghoshal, Charlotte R James, Maxime Lenormand, Thomas Louail, Ronaldo Menezes, José J Ramasco, Filippo Simini, and Marcello Tomasini. Human mobility: models and applications. Physics Reports, 734:1–74, 2018.
- 4
Adrian Dobra, Nathalie E Williams, and Nathan Eagle. Spatiotemporal detection of unusual human population behavior using mobile phone data. PloS one, 10(3):e0120449, 2015.
- 5
Takahiro Yabe, Nicholas KW Jones, Nancy Lozano-Gracia, Maham Faisal Khan, Satish V Ukkusuri, Samuel Fraiberger, and Aleister Montfort. Location data reveals disproportionate disaster impact amongst the poor: a case study of the 2017 puebla earthquake using mobilkit. arXiv preprint arXiv:2107.13590, 2021.
- 6
World Bank. World Development Report 2021 : Data for Better Lives. World Bank, 2021. License: CC BY 3.0 IGO. URL: http://hdl.handle.net/10986/35218.