Conclusion
Development Research in Practice: The DIME Analytics Data Handbook teaches readers to handle data more efficiently, effectively, and ethically at all stages of development research projects. It lays out a start-to-finish vision of the tasks and workflows that a modern development researcher will need to undertake, from planning a project’s measurement framework and data strategy to acquiring and analyzing data to publishing the code and data. Each chapter explores key tasks and concepts and provides links to resources and DIME Wiki pages that provide further details and implementation guidance. This structure is intended to allow readers to return to each chapter as they become progressively more familiar with individual topics.
Bringing it all together
Although each chapter is written to stand alone, the recommended workflows detailed in Development Research in Practice build on each other. Adopting the best practices from early chapters will allow for easier and more intuitive adoption of workflows and tasks in subsequent chapters. From the design and structure of measurement frameworks and data acquisition to the creation of reproducibility packages and data documentation, this book provides the tools and concepts needed to connect all stages of research coherently rather than undertaking them as discrete tasks. Figure 8.1 offers a visual representation of the interconnections among outputs created over the research data life cycle. It shows how different steps are related, as materials created in one step then feed into the next and eventually create a complete publication package for a research product.
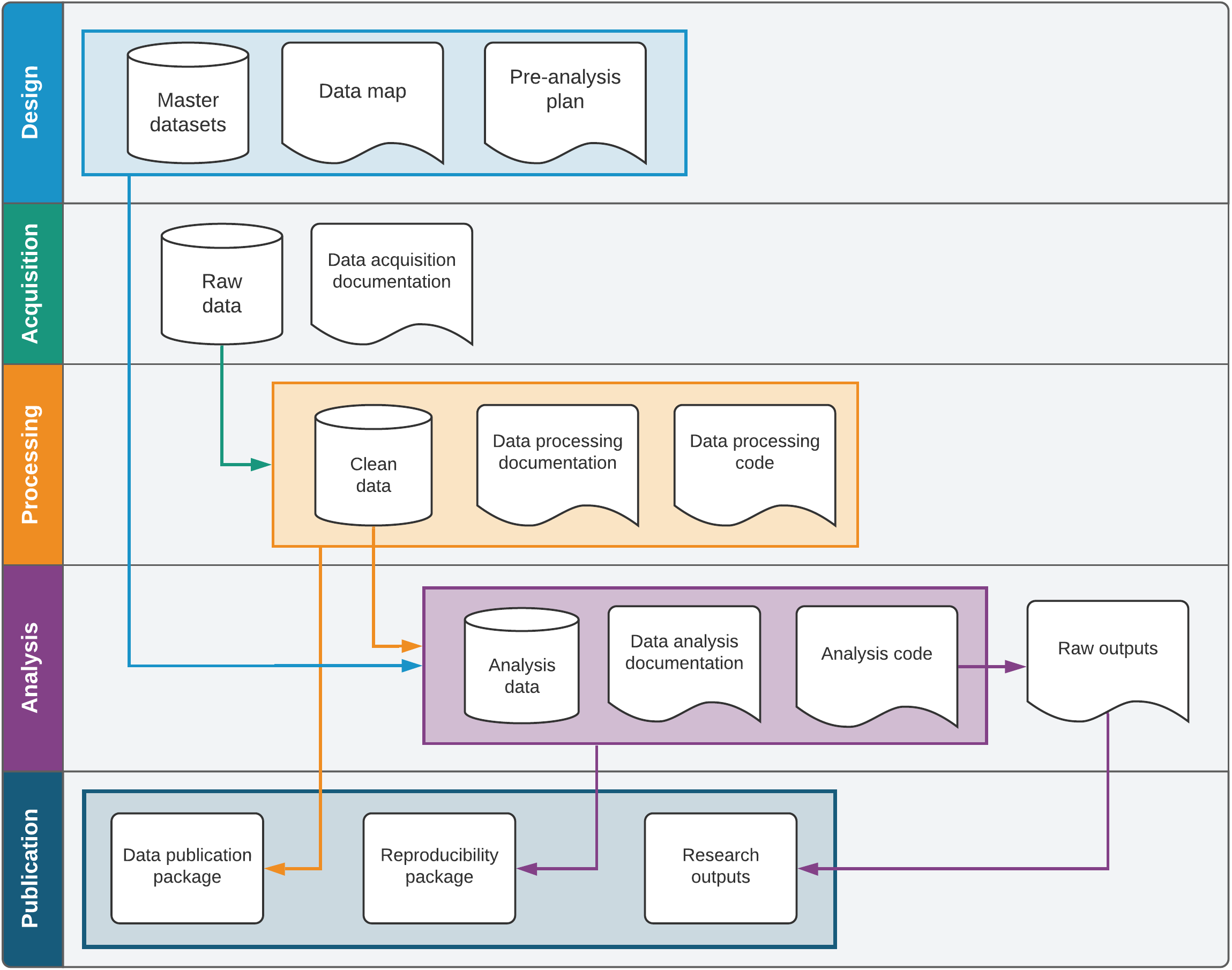
The first chapter begins the book with a discussion of credibility, transparency, and reproducibility in research. The overarching idea is that research should always be accessible and available to others, both within and outside the research team. The handbook treats data work as a “social process” involving multiple team members with different roles and technical abilities. The fundamental theme of accessible open science research provides structure for all subsequent tasks and offers both private and public benefits: data work that is intentionally designed for others to interact with will also be easier for teams to collaborate on and maintain over time.
This idea is carried through to the second chapter, which introduces the reader to the technical tools and concepts needed to develop a work environment conducive to accessible research. An open science approach necessitates cooperation with a diverse group of collaborators using modern approaches to computing technology. It requires collective agreement on specific tools and methods of collaboration and record keeping as well as on technical approaches like version control, file sharing, and directory organization.
The third chapter translates research design into a specific easurement framework and data map. The perspective of reproducible research emphasizes the need to clarify and document how data will describe the research design and record scientific measurements. The documentation-centric data map approach ensures that a research team agrees how multiple data sources are intended to be linked without error and how the structure of those data corresponds to the research design. It also describes how to use these concepts to implement research design through reproducible routines for sampling and randomization and discusses how to analyze and document statistical power.
The fourth chapter turns to modern data acquisition methods and governance frameworks, including data licensing, data ownership, electronic data collection, and data security. Establishing clear data ownership and publication rights at this stage is essential to creating open, reproducible outputs at publication. For researchers undertaking primary data collection, the chapter details how to prepare for and implement high-quality electronic surveys and how to document data structure and data quality. Finally, the chapter describes how to ensure that all data sets are stored properly and securely to protect the privacy of research participants and prevent data loss.
The fifth chapter provides a detailed workflow for data cleaning and processing, emphasizing tidy data, quality control, privacy protection, and documentation. The workflow calls upon outputs created in previous stages, relying on the data map and survey documentation to guide the creation of analysis-ready data sets. The chapter offers specific consideration of how to structure data sets at the correct units of observation, connecting each unit to the project’s overarching measurement framework through appropriate identification variables. By the end of the data-cleaning process, all data points are corrected, variables and values are labeled, duplicates are resolved, and identifying information is removed from working copies of the data sets so they can be processed more rapidly in the analytical stage that follows in the workflow.
The sixth chapter details how to construct data sets that are deliberately structured for analysis, analyze them effectively and efficiently, and generate reproducible outputs. The chapter separates data construction, exploratory analysis, and final analysis—in code as well as in human-readable dynamic documents—so that final outputs can be incorporated easily into research outputs for publication. Separating out the final analysis also has the advantage of producing code that is nearly ready for publication and reproducibility as written, usually requiring only minor modifications for release.
The seventh chapter provides an overview of the workflow required to move research results to publication—no matter the format of the output—as well as the tools and practices for making research publicly accessible. It becomes clear that following recommended practices at all stages of the research life cycle greatly simplifies the final publication process. The chapter gives extensive attention to the collaborative preparation of research outputs, bringing together technical outputs like figures and tables with versatile formatting, collaboration, and version-control tools in LaTeX documents. It then provides guidelines both for releasing and licensing data in a way that balances the twin responsibilities of privacy and access and for structuring code so that it is accessible and useful to other readers. The final output is a reproducibility package that brings together all of the final materials from the project in a single location, fulfilling the goals laid out in the first chapter.
Where to go from here
Throughout Development Research in Practice, the narrative provides enough detail for readers to understand the purpose and function of each of the core research steps and how they link together. For readability, the number of technical details and implementation guidelines provided directly in the text is limited. Instead, this book provides a wide variety of resources for readers to continue building their knowledge and skills. Sidenotes throughout the book link to DIME Wiki pages detailing specific protocols, code conventions, and field procedures that DIME considers best practices. References to theoretical papers are included to help researchers to figure out how to handle the unique cases that will undoubtedly arise, and references to examples of various techniques and situations are also provided throughout.
The book includes case studies from the Demand for Safe Spaces project, which are used to show how the research tasks described are implemented in practice and eventually prepared and released to the public. By accessing the various repositories and resources linked from the Demand for Safe Spaces case study, readers can examine the original materials and research outputs from a completed DIME project in detail, including the code and data used to produce them.
This edition of Development Research in Practice also has three appendixes covering important topics that do not fall within the research workflow at any particular point. Appendix A, the DIME Analytics Coding Guide, includes a general discussion of considerations for writing good code as part of a research team and instructions for accessing the code examples throughout the book, and the style guide that DIME uses for coding in Stata. Appendix B, the DIME Analytics Resource Directory, provides pointers and descriptions for the materials, trainings, code tools, and other public goods produced by DIME Analytics to improve the quality of development research. Appendix C, which focuses on research design for impact evaluation, provides an overview of modern methods for work in causal inference and program evaluation, with extensive links to the DIME Wiki and references to the literature.
This diverse set of resources is intended to allow readers to continue learning at the level of detail that is appropriate to their role. It provides accessible and useful approaches for everyone seeking to improve their understanding of the research process or its practical considerations—from project managers and principal investigators to research assistants and field staff to students as well as to research partners and consumers. The introduction to each chapter includes key responsibilities for different members of a typical research team. A useful first task for a research team after reading this book would be to discuss these key responsibilities in the context of the team’s research projects.
The DIME Analytics team hopes that this book, its appendixes, and the wide range of resources and examples highlighted throughout will serve as a useful guide for anyone who participates in or interacts with development research. The book is also a living document, with a live version available online at https://worldbank.github.io/dime-data-handbook and a GitHub repository for inputs, discussions, and revisions at https://github.com/worldbank/dime-data-handbook. Both are publicly available, and readers are invited to participate in the active improvement of this book and all of the related resources that DIME Analytics maintains, especially the DIME Wiki (https://dimewiki.worldbank.org).