Chapter 4 Acquiring development data
Many research questions require original data because no source of publicly available data addresses the inputs or outcomes of interest for the relevant population. Data acquisition can take many forms, including primary data generated through surveys; private sector partnerships granting access to new data sources, such as administrative and sensor data; digitization of paper records, including administrative data; web scraping; data captured by unmanned aerial vehicles or other types of remote sensing; and novel integration of various types of data sets, such as combining survey and sensor data. Much of the recent push toward credibility in the social sciences has focused on analytical practices. However, credible development research depends, first and foremost, on the quality of the data acquired. Clear and careful documentation of the data acquisition process is essential for research to be reproducible.
This chapter covers reproducible data acquisition, special considerations for generating high-quality survey data, and protocols for handling confidential data safely and securely. The first section discusses acquiring data reproducibly, by establishing and documenting the right to use the data. This discussion applies to all original data, whether collected for the first time through surveys or sensors or acquired through a unique partnership. The second section examines the process of acquiring data through surveys, which is typically more involved than acquiring secondary data and has more in-built opportunities for quality control. It provides detailed guidance on the electronic survey workflow, from designing electronic survey instruments to monitoring data quality once fieldwork is ongoing. The final section discusses handling data safely, providing guidance on how to receive, transfer, store, and share confidential data. Secure file management is a basic requirement for complying with the legal and ethical agreements that allow access to personal information for research purposes. Box 4.1 summarizes the main points, lists the responsibilities of different members of the research team, and supplies a list of key tools and resources for implementing the recommended practices.
BOX 4.1 SUMMARY: ACQUIRING DEVELOPMENT DATA
The process of obtaining research data is unique to every project. However, some basic structures and processes are common to both data acquired from others and data generated by surveys:
- When receiving data from others, ownership and licensing are critical. Before any data are transferred, knowing all of the formal rights associated with those data is essential:
- Ensure that the partner has the right to share the data, especially data containing personally identifying information.
- Identify the data owner and any restrictions on the use, storage, or handling of data.
- Secure a data use agreement or license from the partner, outlining the rights and responsibilities regarding analysis, publication of results and derived data, redistribution of data, and data destruction.
- Collecting high-quality data requires careful planning and attention to detail throughout the workflow. The following best practices apply to all surveys, with further details for electronic surveys:
- Produce and pilot draft instruments on paper and focus on survey content.
- Structure questionnaires for electronic programming and pilot them for function, considering features like pagination, ordering, looping, conditional execution, and instructions for enumerators.
- Test data outputs for analytical compatibility, such as code-friendly variable and value labels.
- Train enumerators carefully, using a paper survey before an electronic template, assess their performance objectively throughout training, and transparently select the top performers.
- Assess data quality in real time, through scripted high-frequency checks and diligent field validation.
- No matter how data are acquired, handling data securely is essential:
- Encrypt data on all devices, in transit and at rest, beginning from the point of collection and including all intermediate locations such as servers and local devices.
- Store encryption keys using appropriate password management software with strong, unique passwords for all applications and devices with access.
- Back up data in case of total loss or failure of hardware and software at any site.
Key responsibilities for task team leaders and principal investigators
- Obtain appropriate legal documentation and permission agreements for all data.
- For surveys, guide and supervise development of all instruments.
- For surveys, review and provide inputs to the project’s data quality assurance plan.
- For surveys, guide decisions on how to correct issues identified during data quality checks.
- Oversee implementation of security measures and manage access codes, encryption keys, and hardware.
- Determine and communicate institutionally appropriate data storage and backup plans.
Key responsibilities for research assistants
- Coordinate with data providers, develop required technical documentation, and archive all final documentation.
- For surveys, draft, refine, and program all survey instruments, following best practices for electronic survey programming and maintaining up-to-date and version-controlled paper and electronic versions.
- For surveys, coordinate closely with field staff on survey pilots and contribute to enumerator manuals.
- For surveys, draft a data quality assurance plan and manage the quality assurance process.
- Implement storage and security measures for all data.
Key resources
- Manage Successful Impact Evaluation Surveys, a course covering best practices for the survey workflow, from planning to piloting instruments and monitoring data quality, at https://osf.io/resya
- DIME Analytics Continuing Education for field coordinators, technical trainings and courses for staff implementing field surveys that are updated regularly, at https://osf.io/gmn38
- SurveyCTO coding practices, a suite of DIME Wiki articles covering common approaches to sophisticated design and programming in SurveyCTO, at https://dimewiki.worldbank.org/SurveyCTO_Coding_Practices
- Monitoring data quality, a DIME Wiki article covering communication, field monitoring, minimizing attrition, back-checks, and data quality checks, at https://dimewiki.worldbank.org/Monitoring_Data_Quality
Acquiring data ethically and reproducibly
Clearly establishing and documenting access to data are critical for reproducible research. This section provides guidelines for establishing data ownership, receiving data from development partners, and documenting the research team’s right to use data. Researchers are responsible not only for respecting the rights of both people who own and people who are described by the data but also for making that information as available and as accessible as possible. These twin responsibilities can and do come into tension, so it is important for everyone on the team to be informed about what everyone else is doing. Writing down and agreeing to specific details is a good way to do that.
Determining data ownership
Before acquiring any data, it is critical to establish data ownership56. Data ownership can sometimes be challenging to establish, because different jurisdictions have different laws regarding data and information, and the research team may have its own regulations. In some jurisdictions, data are implicitly owned by the people to whom the information pertains. In others, data are owned by the people who collect the information. In still others, ownership is highly unclear, and there are varying norms. The best approach is always to consult with a local partner and to enter into specific legal agreements establishing ownership, access, and publication rights. These agreements are particularly critical when confidential data are involved—that is, when people are disclosing information that could not be obtained simply by observation or through public records.
If the research team is requesting access to existing data, it must enter into data license agreements to access the data and publish research outputs based on the information. These agreements should make clear from the outset whether and how the research team can make the original data public or whether it can publish any portion or derivatives57 of the data. If the data are publicly accessible, these agreements may be as simple as agreeing to terms of use on the website from which the data can be downloaded. If the data are original and not yet publicly accessible, the process is typically more complex and requires a documented legal agreement or memorandum of understanding.
If the research team is generating data directly, such as survey data, it is important to clarify up front who owns the data and who will have access to the information (see box 4.2 for an example of how data ownership considerations may vary within a project). These details need to be shared with respondents when they are offered the opportunity to consent to participate in the study. If the research team is not collecting the data directly—for example, if a government, private company, or research partner is collecting the data—an explicit agreement is needed establishing who owns the resulting data.
BOX 4.2 DETERMINING DATA OWNERSHIP: A CASE STUDY FROM THE DEMAND FOR SAFE SPACES PROJECT
The Demand for Safe Spaces study used three data sources, all of which had different data ownership considerations.
- Crowdsourced ride data from the mobile app. The research team acquired crowdsourced data through a contract with the technology firm responsible for developing and deploying the application. The terms of the contract specified that all intellectual property in derivative works developed using the data set are the property of the World Bank.
- Platform survey and implicit association test data. A small team of consultants collected original data using a survey instrument developed by the research team. The contract specified that the data collected by the consultants and all derivative works are the sole intellectual property of the World Bank.
- Crime data. The team also used one variable (indicating crime rate at the Supervia stations) from publicly accessible data produced by Rio’s Public Security Institute. The data are published under Brazil’s Access to Information Law and are available for download from the institute’s website.
The contract for data collection should include specific terms as to the rights and responsibilities of each stakeholder. It must clearly stipulate which party owns the data produced and that the research team maintains full intellectual property rights. The contract should also explicitly indicate that the contracted firm is responsible for protecting the privacy of respondents, that the data collection will not be delegated to any third parties, and that the data will not be used by the firm or subcontractors for any purpose not expressly stated in the contract, before, during, or after the assignment. The contract should also stipulate that the vendor is required to comply with ethical standards for social science research and to adhere to the specific terms of agreement with the relevant institutional review board58 (IRB) or applicable local authority. Finally, it should include policies on the reuse, storage, and retention or destruction of data.
Research teams that acquire original data must also consider data ownership downstream, through the terms they use to release those data to other researchers or to the general public. The team should consider whether it can publish the data in full after removing personal identifiers. For example, the team must consider whether it would be acceptable for the data to be copied and stored on servers anywhere in the world, whether it would be preferable to manage permissions on a case-by-case basis, and whether data users would be expected to cite or credit them. Similarly, the team can require users to release the derivative data sets or publications under similar licenses or offer use without restriction. Simple license templates are available for offering many of these permissions, but, at the planning stage, all licensing agreements, data collection contracts, and informed consent processes used to acquire the data need to detail those future uses specifically.
Obtaining data licenses
Data licensing59 is the formal act of the owner giving some rights to a specific user, while retaining ownership of the data set. If the team does not own the data set to be analyzed, it must enter into a licensing agreement to access the data for research purposes. Similarly, if the team does own a data set, it must consider whether the data set will be made accessible to other researchers and what terms of use will be required.
If the research team requires access to existing data for novel research, it is necessary to agree on the terms of use with the data owner, typically through a data license agreement. These terms should specify what data elements will be received, the purposes for which the data will be used, and who will have access to the data. The data owner is unlikely to be highly familiar with the research process and may be surprised at some of the uses to which the data could be put. It is essential to be forthcoming about the uses up front. Researchers typically want to hold intellectual property rights to all research outputs developed with the data and a license for all uses of derivative works, including public distribution (unless ethical considerations contraindicate this right). Holding these rights allows the research team to store, catalog, and publish, in whole or in part, either the original licensed data set or data sets derived from the original. It is important to ensure that the license obtained from the data owner allows these uses and that the owner is consulted if exceptions for specific portions of the data are foreseen.
The Development Impact Evaluation (DIME) department follows the World Bank’s template data license agreement. The template specifies the specific objectives of the data sharing and whether the data can be used for the established purpose only or for other objectives as well. It classifies data into one of four access categories, depending on who can access the data by default and whether case-by-case authorization for access is needed. The data provider may impose similar restrictions on sharing derivative data and any or all of the associated metadata. The template also specifies the required citation for the data. Although it is not necessary to use the World Bank’s template or its access categories if the team is not working on a World Bank project, the information in the template is useful in two ways. First, it is necessary to base the data license agreement on a template. Ad hoc agreements can leave many legal ambiguities or gaps where the permissions given to the research team are unclear or incomplete. Second, it is strongly recommended that the data be categorized using some variation of this system. Doing so will create different standard procedures for each category, so that the intended processes for handling the data are clear.
Documenting data received from partners
Research teams granted access to existing data may receive those data in several ways: access to an existing server, physical access to extract certain information, or a one-time data transfer. In all cases, action is required to ensure that data are transferred through secure channels so that confidentiality is not compromised. The section on handling data securely explains how to do that. Compliance with ethical research standards may in some cases require a stricter level of security than initially proposed by the partner agency. It is also critical to request any and all available documentation for the data; this documentation could take the form of a data dictionary or codebook, a manual for the administrative data collection system, detailed reports or operating procedures, or another format. If no written documentation is available, the person(s) responsible for managing the data should be interviewed to learn as much as possible about the data; the interview notes should be archived with data documentation.
At this stage, it is very important to assess the documentation and cataloging
of data and associated metadata. It is not always clear what pieces of
information will jointly constitute a research data set, and many data sets are
not organized for research. The original data should be retained exactly as
received, alongside a copy of the corresponding ownership agreement or license.
A simple README document is needed, noting the date of receipt, the source and
recipient of the data, and a brief description of each file received. All too
often data are provided in vaguely named spreadsheets or digital files with
nonspecific titles. Documentation is critical for future access and
reproducibility.
Eventually, a set of documents will be created that can be submitted to a data catalog and given a reference and citation. Metadata— documentation about the data—are critical for future use of the data. Metadata should include documentation of how the data were created, what they measure, and how they are to be used. For survey data, this documentation should include the survey instrument and associated manuals; the sampling protocols and field adherence to those protocols and any sampling weights; what variable(s) uniquely identifies the data set(s) and how different data sets can be linked; and a description of field procedures and quality controls. DIME uses the Data Documentation Initiative (DDI), which is supported by the World Bank’s Microdata Catalog (https://microdata.worldbank.org).
As soon as the desired pieces of information are stored together, it is time to think about which ones are the components of what will be called a data set. Often, when receiving data from a partner, even highly structured materials such as registers or records are not, as received, equivalent to a research data set; they require initial cleaning, restructuring, or recombination to be considered an original research data set. This process is as much an art as a science: it is important to keep information together that is best contextualized together, but information also needs to be as granular as possible, particularly when there are varying units of observation. There is often no single correct way to structure a data set, and the research team will need to decide how to organize the materials received. Soon, research data sets will be built from this set of information and become the original clean data, which will be the material published, released, and cited as the starting point of the data. (If funders or publishers request that “raw” data be published or cataloged, for example, they should receive this data set, unless they specifically require data in the original format received.) These first data sets created from the received materials need to be cataloged, licensed, and prepared for release. This is a good time to begin assessing the disclosure risk60 and to seek publication licenses in collaboration with data providers, while still in close contact with them.
Collecting high-quality data using electronic surveys
This section details specific considerations for acquiring high-quality data through electronic surveys of study subjects. If the project will not use any survey data, skip this section. Many excellent resources address how to design questionnaires and field supervision, but few cover the particular challenges and opportunities presented by electronic surveys. Many survey software options are available to researchers, and the market is evolving rapidly. Therefore, this section focuses on specific workflow considerations for digitally collected data and on basic concepts rather than on software-specific tools.
Electronic data collection technologies have greatly accelerated the ability to collect high-quality data using purpose-built survey instruments and therefore have improved the precision of research. At the same time, electronic surveys create new pitfalls to avoid. Programming electronic surveys efficiently requires a very different mindset than writing paper-based surveys; careful preparation can improve the efficiency and data quality of surveys. This section outlines the major steps and technical considerations to follow when fielding a custom survey instrument, no matter the scale.
Designing survey instruments
A well-designed questionnaire results from careful planning, consideration of analysis and indicators, close review of existing questionnaires, survey pilots, and research team and stakeholder review. Many excellent resources discuss questionnaire design61, such as that of the World Bank’s Living Standards Measurement Survey (Glewwe and Grosh (2000)). This section focuses on the design of electronic field surveys, often referred to as computer-assisted personal interviews62 (CAPIs). Although most surveys are now collected electronically, by tablet, mobile phone, or web browser, questionnaire design (content development) and questionnaire programming (functionality development) should be seen as two strictly separate tasks. Therefore, the research team should agree on the content of all questionnaires and design a version of the survey on paper before beginning to program the electronic version. Doing so facilitates a focus on content during the design process and ensures that teams have a readable, printable version of the questionnaire. Most important, it means that the research, not the technology, drives the questionnaire’s design.
This approach is recommended for three reasons. First, an easy-to-read paper questionnaire is very useful for training data collection staff, which is discussed further in the section on training enumerators. Second, finalizing the paper version of the questionnaire before beginning any programming avoids version-control concerns that arise from concurrent work on paper and electronic survey instruments. Third, a readable paper questionnaire is a necessary component of data documentation, because it is difficult to work backward from the survey program to the intended concepts.
The workflow for designing a questionnaire is much like writing an essay: it begins from broad concepts and slowly fleshes out the specifics. It is essential to start with a clear understanding of the theory of change63 and research design64 of the project. The first step of questionnaire design is to list key outcomes of interest, the main covariates to control for, and any variables needed for the specific research design. The ideal starting point for this process is a preanalysis plan65.
The list of key outcomes is used to create an outline of questionnaire modules. The modules are not numbered; instead, a short prefix is used, because numbers quickly become outdated when modules are reordered. For each module, it is necessary to determine if the module is applicable to the full sample or only to specific respondents and whether or how often the module should be repeated. For example, a module on maternal health applies only to households with a woman who has children, a household income module should be answered by the person responsible for household finances, and a module on agricultural production might be repeated for each crop cultivated by the household. Each module should then be expanded into specific indicators to observe in the field. To the greatest extent possible, using questions from reputable survey instruments that have already been fielded is recommended rather than creating questions from scratch (for links to recommended questionnaire libraries, see the DIME Wiki at https://dimewiki.worldbank.org/Literature_Review_for_Questionnaire ). Questionnaires for impact evaluation must also include ways to document the reasons for attrition and treatment contamination. These data components are essential for completing CONSORT records, a standardized system for reporting enrollment, intervention allocation, follow-up, and data analysis through the phases of a randomized trial (Begg et al. (1996)).
Piloting survey instruments
A survey pilot66 is critical to finalize survey design. The pilot must be done out-of-sample, but in a context as similar as possible to the study sample. The survey pilot includes three steps: a prepilot, a content-focused pilot, and a data-focused pilot (see box 4.3 for a description of the pilots for the Demand for Safe Spaces project).
The first step is a prepilot. The prepilot is a qualitative exercise, done early in the questionnaire design process. The objective is to answer broad questions about how to measure key outcome variables and gather qualitative information relevant to any of the planned survey modules. A prepilot is particularly important when designing new survey instruments.
The second step is a content-focused pilot. The objectives at this stage are to improve the structure and length of the questionnaire, refine the phrasing and translation of specific questions, check for potential sensitivities and enumerator-respondent interactions, and confirm that coded-response options are exhaustive. In addition, it provides an opportunity to test and refine all of the survey protocols, such as how units will be sampled or preselected units identified. The content-focused pilot is best done with pen and paper, before the questionnaire is programmed, because changes resulting from this pilot may be deep and structural, making them hard to adjust in code. At this point, it is important to test both the validity and the reliability of the survey questions, which requires conducting the content-focused pilot with a sufficiently large sample (the exact requirement will depend on the research sample, but a very rough rule of thumb is a minimum of 30 interviews). For a checklist for how to prepare for a survey pilot, see the DIME Wiki at https://dimewiki.worldbank.org/Checklist:_Preparing_for_a_Survey_Pilot. The sample for the pilot should be as similar as possible to the sample for the full survey, but the two should never overlap. For details on selecting appropriate pilot respondents, see the DIME Wiki at https://dimewiki.worldbank.org/Survey_Pilot_Participants . For checklists detailing activities in a content-focused pilot, see the DIME Wiki at https://dimewiki.worldbank.org/Checklist:_Content-focused_Pilot and https://dimewiki.worldbank.org/Checklist:_Piloting_Survey_Protocols .
The final stage is a data-focused pilot. After the content is finalized, it is time to begin programming a draft version of the electronic survey instrument. The objective of this pilot is to refine the programming of the questionnaire; this process is discussed in detail in the following section.
BOX 4.3 PILOTING SURVEY INSTRUMENTS: A CASE STUDY FROM THE DEMAND FOR SAFE SPACES PROJECT
The context for the platform survey and implicit association test presented some unique design challenges. The respondents to the survey were commuters on the platform waiting to board the train. Given the survey setting, respondents might need to leave at any time, so only a random subset of questions was asked to each participant. The survey included a total of 25 questions on commuting patterns, preferences about use of the reserved car, perceptions about safety, and perceptions about gender issues and how they affect riding choices. While waiting for their train, 1,000 metro riders answered the survey. The team tested the questions extensively through pilots before commencing data collection. On the basis of pilot data and feedback, questions that were causing confusion were reworded, and the questionnaire was shortened to reduce attrition. The research team designed a custom instrument to test for implicit association between using or not using the women-reserved space and openness to sexual advances. To determine the best words to capture social stigma, two versions of the implicit association test instrument were tested, one with “strong” and one with “weak” language (for example, “vulgar” vs. “seductive”), and the response times were compared to other well-established instruments. For the development of all protocols and sensitive survey questions, the research team requested input and feedback from gender experts at the World Bank and local researchers working on gender-related issues to ensure that the questions were worded appropriately.
For the survey instrument, visit the GitHub repository at https://git.io/JtgqD. For the survey protocols, visit the GitHub repository at https://git.io/Jtgqy.
Programming electronic survey instruments
Once the team is satisfied with the content and structure of the survey, it is time to move on to implementing it electronically. Electronic data collection has great potential to simplify survey implementation and improve data quality. But it is critical to ensure that electronic survey instruments flow correctly and produce data that can be used in statistical software, before data collection begins. Electronic questionnaires are typically developed in a spreadsheet (usually using Excel or Google Sheets) or a software-specific form builder, all of which are accessible even to novice users.
This book does not address software-specific design; rather, it focuses on coding and design conventions that are important to follow for electronic surveys regardless of the choice of software. (At the time of publication, SurveyCTO is the most commonly used survey software in DIME. For best practices for SurveyCTO code, which almost always apply to other survey software as well, see the DIME Wiki at https://dimewiki.worldbank.org/SurveyCTO_Coding_Practices.) Survey software tools provide a wide range of features designed to make implementing even highly complex surveys easy, scalable, and secure. However, these features are not fully automatic: the survey must be designed and managed actively. This section discusses specific practices that take advantage of electronic survey features and ensure that the exported data are compatible with the statistical software used.
From the perspective of quantitative analysis, questions with coded-response options67 are always preferable to open-ended questions68. The content-based pilot is an excellent time to ask open-ended questions and refine fixed responses for the final version of the questionnaire—it is rarely practical to code lots of free text after the full survey has been conducted. Two examples help to illustrate this point. First, instead of asking, “How do you feel about the proposed policy change?” use techniques like Likert scales69. Second, if collecting data on things like medication use or food supplies, collect, for example, the brand name of the product, the generic name of the product, a coded identifier for the item, and the broad category to which each product belongs (for example, “antibiotics” or “staple foods”) (for an example, see Wafula et al. (2017)).
All four identifiers may be useful for different reasons, but the latter two are likely to be the most useful for rapid data analysis. The coded identifiers require providing field staff with a translation dictionary, but also enable automated rapid recoding for analysis with no loss of information. The broad category requires agreement on the groups of interest, but allows for much more comprehensible top-line statistics and data quality checks. Rigorous field testing is required to ensure that the answer categories are comprehensive; additionally, it is best practice always to include an “other, specify” option. Keeping track of such responses in the first few weeks of fieldwork is recommended because adding an answer category for a response frequently showing up as “other” can save time by avoiding extensive coding later in the project.
It is essential to provide variable names and value labels for the fields in the questionnaire in a way that will work well in the data analysis software. Most survey programs do not require such names by default, because naming restrictions vary across statistical software. Instead, most survey software implicitly encourages the use of complete sentences as question labels and detailed descriptions as choice options. This practice is desirable for the enumerator-respondent interaction, but analysis-compatible labels should now be programmed in the background so that the resulting data can be imported rapidly into the analytical software.
There is some debate over how exactly individual questions should be identified:
formats like dem_1 are hard to remember and unpleasant to reorder, but formats
like dem_sex_of_respondent quickly become cumbersome. Using short descriptive
names with clear prefixes is recommended so that variables within a module stay
together when sorted alphabetically—for example, formats like dem_woman.
Variable names should never include spaces or mixed cases (DIME prefers using
all lowercase; for more details on naming conventions, see the DIME Wiki at
https://dimewiki.worldbank.org/Naming_Conventions), and they should not be so
long that the software cuts them off, which could result in a loss of uniqueness
and requires a lot of manual work to restore compatibility. Numbering questions
is discouraged, at least at first, because it makes reordering questions
difficult, which is a common change recommended after the pilot. In the case of
follow-up surveys, numbering can quickly become convoluted, too often resulting
in uninformative variables names like ag_15a, ag_15_new, ag_15_fup2, and
so on.
Using electronic survey features to enhance data quality
Electronic surveys are more than simply a paper questionnaire displayed on a mobile device or web browser. All common survey software products make it possible to automate survey logic and include hard or soft constraints on survey responses. These features make enumerators’ work easier and create an opportunity to identify and resolve data issues in real time, which simplifies data cleaning and improves the quality of responses. Well-programmed questionnaires should include most or all of the following features:
- Localization. The survey instrument should display full-text questions and responses in all potential survey languages and should also have English (or the primary language of the research team) and code-compatible versions of all text and labels.
- Survey logic. Built-in tests should be included for all logic connections between questions, so that only relevant questions appear. Enumerators should not have to implement complex survey logic themselves. The research team should program the instruments to embed simple skip patterns as well as more complex interdependencies (for example, a child health module is asked only of households that report the presence of a child under five).
- Range checks. Range checks should be added for all numeric variables to
catch data entry mistakes (for example,
agemust be less than 120). - Confirmation of key variables. Double entry of essential information (such as a contact phone number in a survey with planned phone follow-up) is required, with automatic validation that the two entries match and with rejection and reentry otherwise.
- Multimedia. Electronic questionnaires facilitate the collection of images, video, and geolocation data directly during the survey, using the camera and global positioning system (GPS) built into the tablet or phone.
- Preloaded data. Data from previous rounds or related surveys can be used to prepopulate certain sections of the questionnaire and be validated during the survey.
- Filtered-response options. Filters dynamically reduce the number of response options (for example, filtering a “cities” choice list based on the state selected).
- Location checks. Enumerators submit their actual location using built-in GPS, to confirm that they are in the right place for the interview.
- Consistency checks. It is essential to check that answers to related questions align and that a warning is triggered if they do not so that enumerators can probe further (for example, if a household reports producing 800 kilograms of maize, but selling 900 kilograms of maize from its own production).
- Calculations. The electronic survey instrument should do all of the math; enumerators should not be asked to do their own calculations.
All established survey software packages include debugging and test options to
correct syntax errors and ensure that the survey instruments will compile
successfully. Such options are not sufficient, however, to ensure that the
resulting data set will load without errors in the data analysis software of
choice. To address this issue, DIME Analytics developed the
ietestform70 command
(https://dimewiki.worldbank.org/ietestform), part of the Stata package
iefieldkit (Bjärkefur, Andrade, and Daniels (2020)). Intended for use during questionnaire
programming and before fieldwork, ietestform tests for best practices in
coding, naming, labeling, and compiling choice lists. Although ietestform is
software specific, many of the tests it runs are general and important to
consider regardless of the software chosen. For example, ietestform tests that
no variable name exceeds 32 characters, the limit in Stata (variable names
exceeding that limit will be truncated and, as a result, may no longer be
unique). It checks whether ranges are included for numeric variables. It also
removes all leading and trailing blanks from response lists, which could be
handled inconsistently across software.
The final stage of survey piloting, the data-focused pilot, should be done at this stage (after the questionnaire is programmed). The data-focused pilot is intended to validate the programming and to export a sample data set. Significant desk-testing of the instrument is required to debug the programming as fully as possible before going into the field. It is important to plan for multiple days of piloting, so that the electronic survey instrument can be debugged or otherwise revised at the end of each day and tested the following day, until no further field errors arise. The data-focused pilot should be done in advance of enumerator training. (For a checklist with best practices important to remember during a data-focused pilot, see the DIME Wiki at https://dimewiki.worldbank.org/Checklist:_Data-focused_Pilot.)
Training enumerators
Once a survey instrument is designed, piloted on paper to refine content, programmed, piloted electronically to refine the data, and fully translated to any local languages, it is time to prepare to train the field staff who will be responsible for conducting interviews. The following guidelines for enumerator training apply regardless of whether data will ultimately be collected in person or remotely, with the only significant differences being in terms of survey protocols and the nature of the field practice (which could be in-person or by phone).
The first step is to develop a detailed enumerator manual. The manual should explain each question in the survey instrument, address any issues that arose during piloting, and cover frequently asked questions. The manual should also describe survey protocols and conventions, such as how to select or confirm the identity of respondents and standardized means for recording responses such as “don’t know.” The enumerator manual serves as the basis for the enumerator training. Dividing the training into two sessions is recommended: first, the training-of-trainers and, then, the enumerator training. The training-of-trainers should include the field supervisors and any other relevant management staff from the organization responsible for data collection and should be led by the research team. The objective is to ensure that the survey leaders are deeply familiar with the survey instrument and protocols, so that they can support and supervise enumerators going forward. The training-of-trainers typically lasts a few days, although the exact length will depend on the complexity of the survey instrument and experience level of the staff. (For more details on how to design an enumerator manual and a template for enumerator manuals, among other materials for survey protocol design, see the DIME Wiki at: https://dimewiki.worldbank.org/Enumerator_Training and https://dimewiki.worldbank.org/Survey_Protocols.
Enumerator training includes all field staff and should be led jointly by the research team and the survey managers. This training typically lasts one to two weeks, although the exact length will depend, again, on the complexity of the survey and experience level of the enumerators; training for particularly challenging surveys may take a full month. Enumerator training has three components: review of the paper questionnaire, review of the electronic survey instrument, and field practice. The training schedule should allow for significant discussion and feedback after each component. Training with a paper survey instrument is critical, even for surveys that will be deployed electronically. Starting with paper ensures that enumerators will focus on the content and structure of the survey before diving into the technical components of the survey software. It is much easier for enumerators to understand the overall flow of a survey instrument and the range of possible participant responses using a paper survey than using a tablet, and it is easier to translate that understanding to digital functionality later. The classroom training should be very interactive, using methods such as role playing and mock interviews to test enumerators’ understanding of survey protocols and modules. The field practice should be supervised carefully to provide individualized feedback to each enumerator.
When first using the digital form of the survey, enumerators should submit data from practice interviews to the server, and the research team should run the standard data quality checks71 to familiarize enumerators with those standards for data quality and how quality issues will be communicated and resolved. It is essential to train more enumerators than required for the survey and to include objective assessments throughout the training. These assessments can take the form of pop quizzes (which should be done daily, using the same software as the survey), points for participation, and a score for the field practice. At the end of the training, the aggregate score should be used to select the final team of enumerators.
Checking data quality in real time
Once all field staff have been trained, it is time to start collecting data. Following the guidance in this handbook will set the stage for collecting quality data. To ensure high-quality data in practice, the research team should develop a data quality assurance plan.72 A key advantage of electronic data collection methods, as compared to traditional paper surveys and one-time data dumps, is the ability to access and analyze the data while they are being collected, allowing issues to be identified and resolved in real time. The process of designing systematic data checks and running them routinely throughout data collection simplifies field monitoring and improves data quality. Two types of checks are important for monitoring data quality: high-frequency quality checks and field validation.
High-frequency data quality checks73 (HFCs) should be scripted before data collection begins, so that data checks can start as soon as data start to arrive. A research assistant should run the HFCs on a daily basis for the duration of the survey. HFCs should include monitoring the consistency and range of responses to each question, validating survey programming, testing for enumerator-specific effects, and checking for duplicate entries and completeness of online submissions vis-à-vis the field log.
HFCs will improve data quality only if the issues they catch are communicated to
the team collecting the data and if corrections are documented and applied to
the data. This effort requires close communication with the field team, so that
enumerators are promptly made aware of data quality issues and have a
transparent system for documenting issues and corrections. There are many ways
to communicate the results of HFCs to the field team, with the most important
being to create actionable information. ipacheck, for example, generates a
spreadsheet with flagged errors; these spreadsheets can be sent directly to the
data collection teams. Many teams display results in other formats, such as
online dashboards created by custom scripts. It is also possible to automate the
communication of errors to the field team by adding scripts to link the HFCs
with a messaging platform. Any of these solutions is possible: what works best
for the team will depend on factors such as cellular networks in fieldwork
areas, whether field supervisors have access to laptops, internet speed, and
coding skills of the team preparing the HFC workflow (see box 4.4. for how data
quality assurance was applied in the Demand for Safe Spaces project).
BOX 4.4 CHECKING DATA QUALITY IN REAL TIME: A CASE STUDY FROM THE DEMAND FOR SAFE SPACES PROJECT
The Demand for Safe Spaces project created protocols for checking the quality of the platform survey data. In this case, the survey instrument was programmed for electronic data collection using the SurveyCTO platform.
- Enumerators submitted surveys to the server upon completion of interviews.
- The team’s field coordinator made daily notes of any unusual field occurrences in the documentation folder in the project folder shared by the research team.
- The research team downloaded data daily; after each download the research assistant ran coded data quality checks. The code was prepared in advance of data collection, based on the pilot data.
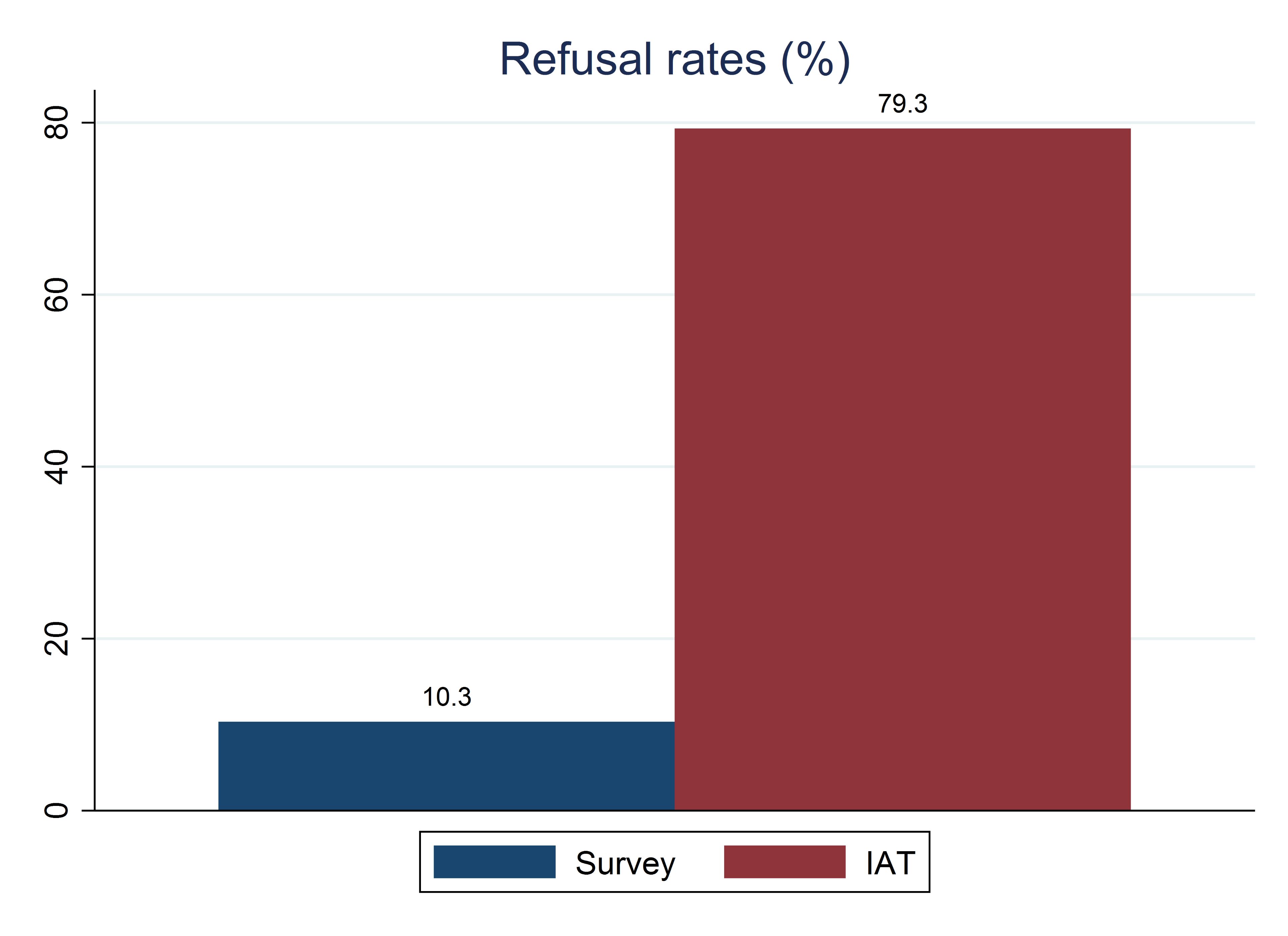
- The data quality checks flagged any duplicated identifications, outliers, and inconsistencies in the day’s data. Issues were reported to the field team the next day. In practice, the only issues flagged were higher-than-expected rates of refusal to answer and wrongly entered identification numbers. The field team responded on the same day to each case, and the research assistant documented any resulting changes to the data set through code.
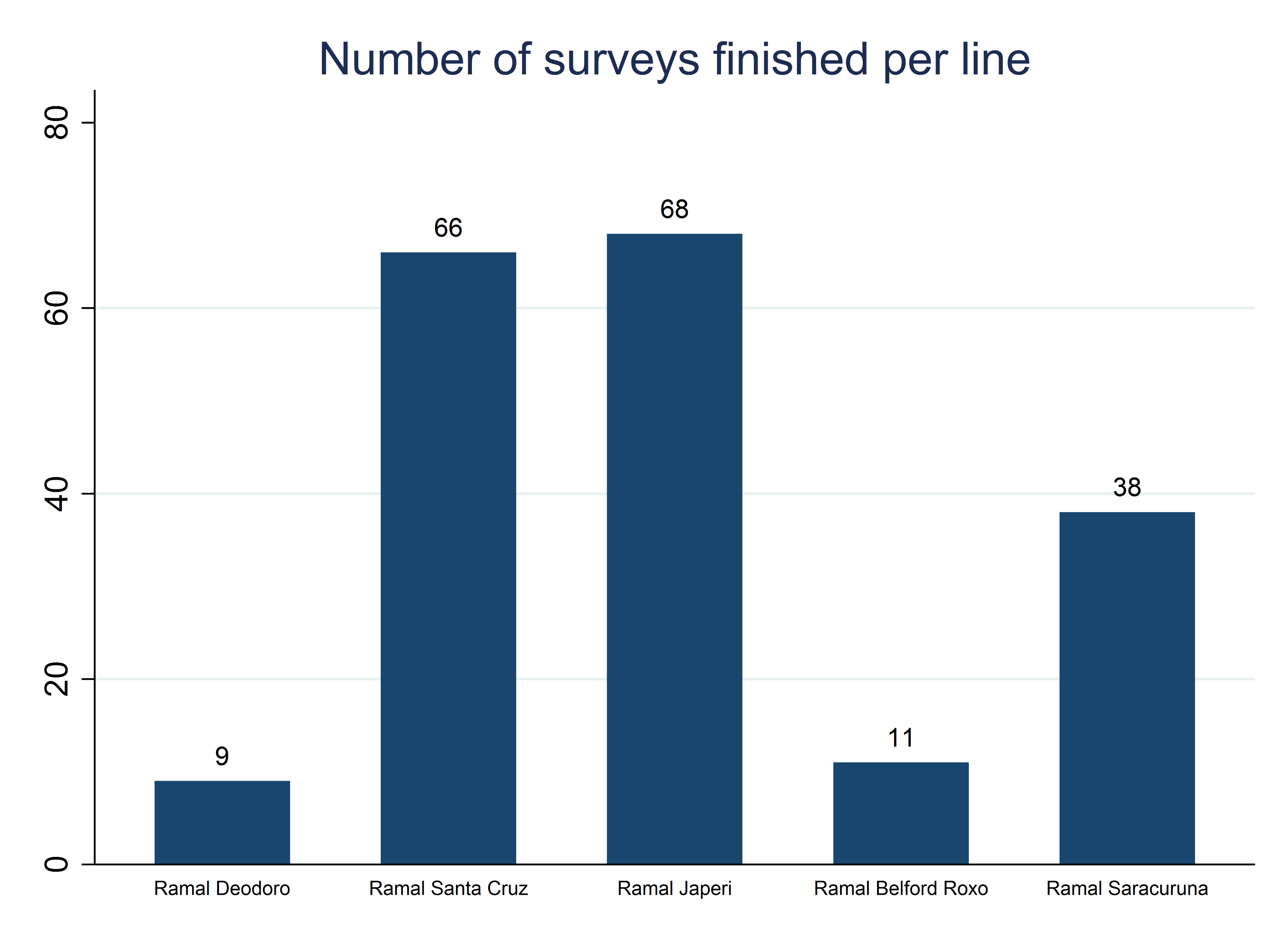
The team developed a customized data quality monitoring dashboard to keep all team members up to date on the survey’s progress and quality. The dashboard included indicators of progress such as refusal rates, number of surveys completed, and number of respondents on the previous day or week by gender. Figure B4.4.1 presents an example of the progress indicators on the dashboard. The dashboard also illustrated participation in the implicit association test, by gender and by various demographic characteristics of interest. Visual descriptive statistics for the main variables of interest were also displayed to monitor and flag concerns easily.
Careful field validation is essential for high-quality survey data. Although it is impossible to control natural measurement errors (for an example, see Kondylis, Mueller, and Zhu (2015)), which are the result of variation in the realization of key outcomes, there is often an opportunity to reduce errors arising from inaccuracies in the data generation process. Back-checks74, spot checks, and other validation audits help to ensure that data are not falsified, incomplete, or otherwise suspect. Field validation also provides an opportunity to ensure that all field protocols are followed. For back-checks, a random subset of observations is selected, and a subset of information from the full survey is verified through a brief targeted survey with the original respondent. For spot checks, field supervisors (and, if contextually appropriate, research team staff) should make unannounced field visits to each enumerator, to confirm first-hand that the enumerator is following survey protocols and understands the survey questions well. The design of the back-checks or validations follows the same survey design principles discussed above: the analysis plan or a list of key outcomes is used to establish which subset of variables to prioritize and to focus on errors that would be major flags of poor-quality data.
Real-time access to the data massively increases the potential utility of
back-checks and both simplifies and improves the rigor of the associated
workflows. Raw data can be used to draw the back-check or validation sample,
which ensures that the validation is apportioned correctly across observations.
As soon as HFCs are complete, the back-check data can be tested against the
original data to identify areas of concern in real time. The bcstats command is
a useful tool for analyzing back-check data in Stata (White (2016)). Some
electronic survey software also provides a unique opportunity to do audits
through audio recordings of the interview, typically short recordings triggered
at random throughout the questionnaire. Such audio audits can be a useful means
to assess whether enumerators are conducting interviews as expected. However,
they must be included in the informed consent for the respondents, and the
recordings will have to be assessed by specially trained staff.
Handling data securely
All confidential data must be handled so that only people specifically approved by an IRB or specified in the data license agreement can access the data. Data can be confidential for multiple reasons; two very common reasons are that the data contain personally identifying information75 (PII) or that the data owner has specified restricted access.
Encrypting data
Data encryption76 is a group of tools and methods to prevent unauthorized access to confidential files. Encryption is a system that is only as secure as its weakest link. Therefore, proper encryption can rarely be condensed into a single tool or method, because the data must be handled securely as they travel through many servers, devices, and computers from the source of the data to the final analysis. This section recommends a streamlined encryption workflow, so that it is as straightforward as possible to ensure that the entire chain is easy to manage and sufficiently secure. For more about data security and encryption practices, see the DIME Wiki at https://dimewiki.worldbank.org/Data_Security or pillar 4 of the DIME Research Standards at https://github.com/worldbank/dime-standards.
All encryption relies on a password or encryption key for both encrypting and decrypting information. Encryption makes data files completely unusable to anyone who does not have the decryption key. This is a higher level of security than most password protection, because password-protected information is often readable if the password is bypassed or the storage hard drive is compromised. Encryption keys have to be shared and stored carefully; if they are lost or cannot be matched to encrypted information, the information is permanently lost. Therefore, access to encryption keys should be treated the same as access to confidential information. These passwords or keys should never be shared by email, WhatsApp, or other common modes of communication; instead, using a secure password manager built for this purpose is recommended. (For DIME’s step-by-step guide for how to get started with password managers, see pillar 4 of the DIME Research Standards at https://github.com/worldbank/dime-standards.)
There are two main types of encryption algorithms: symmetric encryption and asymmetric encryption. In symmetric encryption, the same key is used both to encrypt and to decrypt the data. In asymmetric encryption, one key is used to encrypt data, and another key from the same “pair” is used to decrypt data. It is essential to keep track of these keys. While encryption keys for asymmetric encryption are often provided automatically to the devices recording or inputting information, only people listed on the IRB should have access to decryption keys or any key used in symmetric encryption.
There are two important contexts for encryption. Encryption-in-transit protects data sent over the internet. It is a standard, passive protection that almost all internet-based services use; it rarely needs to be implemented by the research team unless the project is creating a custom transfer solution. Encryption-at-rest protects data stored on a server, computer, or drive.
Typically, unless the project has access to an approved enterprise version of data-sharing software, encryption-at-rest will have to be set up for data in two locations: server or web storage during data acquisition and local storage afterward. It is never wise to assume that encryption-at-rest is implemented automatically unless a cybersecurity expert within the organization has specified that a specific service is appropriate to the particular case. In all other cases, readers should follow the steps laid out in this section to set up their own encryption for which they, and only they, are in full control of who has access to the key.
Collecting and storing data securely
Most data collection software will automatically encrypt all data in transit (that is, uploaded from the field or downloaded from the server). However, it is necessary to ensure that confidential data are protected when stored on a server owned by the data collection software provider or when people not on the research team (including local IT support or system administrators trusted by the research team) can access the location where the information is stored. In most data collection platforms, users need to enable and operate encryption-at-rest explicitly. When collecting data, the tablets or the browsers used for data collection should encrypt all information before submitting it to the server; information should be decrypted only after it has been downloaded to the computer where the data will be used.
This case is perfect for using asymmetric encryption in which two keys form a “public-private key pair.” The public key can safely be sent to all tablets or browsers so that it can be used for encrypting the data before the information is submitted to the server. Only the private key in the same key pair can be used to decrypt those data so the information can be accessed after it has been received. The private key should be kept secret and not given to anyone not listed on the IRB. Again, it is essential to store the key pair in a secure location, such as a secure note in a password manager, because there is no way to access the data if the private key is lost. If the data collection service allows users to view data in a web browser, then the encryption is implemented correctly only if the user is asked for the key each time or is allowed to see only fields explicitly marked as publishable by the research team.
The data security standards that apply when receiving confidential data from the field also apply when transferring confidential data to the field, such as sampling or enumeration lists containing PII. In some survey software, the same encryption that is used to receive data securely from the field can also be used to send confidential data, such as an identifying list of respondents, to the field. Otherwise, it is necessary to create an encrypted folder where the file is stored, transfer this folder to the field team using any method, and have them decrypt the information locally using a key that is transferred securely using a password manager. This process is more similar to the process for storing data securely, which is discussed next.
Before planning how to send or receive data securely, it is necessary to plan how to store data securely after the information has been transferred. Typically, data should be stored so that the information can be decrypted and accessed, interacted with, and then encrypted again. (Usually, these data will not be edited, but nonsensitive pieces may be extracted to a less secure location.) This case is perfect for using symmetric encryption to create an encrypted folder for which the same key is used both to encrypt and to decrypt the information. This type of encryption is similar to a physical safe, for which one key is used to both add and access contents.
An encrypted folder can be set up using, for example, VeraCrypt. Users can interact with and modify files in an encrypted folder if and only if they have the key. This is an example of the implementation of encryption-at-rest. There is absolutely no way to restore the data if the key is lost, so it is impossible to overstress the importance of using a password manager, or an equally secure solution, to store these encryption keys.
It is becoming more and more common for development research to use data that are too big to be stored on a regular computer and need to be stored and processed in a cloud environment instead. Many cloud storage solutions are available, and it is necessary to understand how the data are encrypted and how the keys are handled. In this case, the research team will probably have to ask a cybersecurity expert. After a secure cloud storage is set up, it is vital to remember to encrypt the data if samples are downloaded to—for example, to develop code on—a local computer.
Backing up original data
In addition to encrypting data, protection is needed to keep the information from being accidentally overwritten or deleted. This protection is achieved through a backup protocol, which creates additional copies of the original data, exactly as received and finalized, in secure locations that remain permanently available but are not intended for frequent access. The following is an example of such a protocol:
Create an encrypted folder on a local computer in the shared project folder using VeraCrypt.
Download the original data from the data source to the encrypted folder. If the data source is a survey and the data were encrypted during data collection, both keys will be needed: the private key used during data collection will be needed to download the data and the key used when creating the encrypted folder will be needed to save the information there. This is the working copy of the original data, and it is the copy that will be the starting point for data cleaning.
Create a second encrypted folder on an external drive that is kept in a location where it is physically secure. The data downloaded in the previous step will be copied to this second encrypted folder. This is the master backup copy of the original data. No one should ever work with these data on a day-to-day basis. The encrypted folder for the master backup copy must not be the same encrypted folder used for the working copy. It should not use the same key, because if the same key is used and lost, access to both encrypted folders will be lost. If it is possible to store the external drive in a locked physical safe, then it is not necessary to encrypt the data, thereby removing the risk associated with losing encryption keys.
Finally, create a third encrypted folder. Either create this folder on a computer and upload it to a long-term cloud storage service (not a sync software) or create it on another external hard drive or computer that is then stored in a second location—for example, in another office. This is the golden master backup copy of the original data. The golden master copy should never be stored in a synced folder, because it will be deleted in the cloud storage if it is deleted on the computer. These data exist for recovery purposes only; they are not to be worked on or changed.
This handling satisfies the 3-2-1 rule: there are two onsite copies of the data and one offsite copy, so the data can never be lost in the event of hardware failure. If all goes well, it will never be necessary to access the master or golden master copies—but it is important to know that they are there, safe, if they are ever needed.
Looking ahead
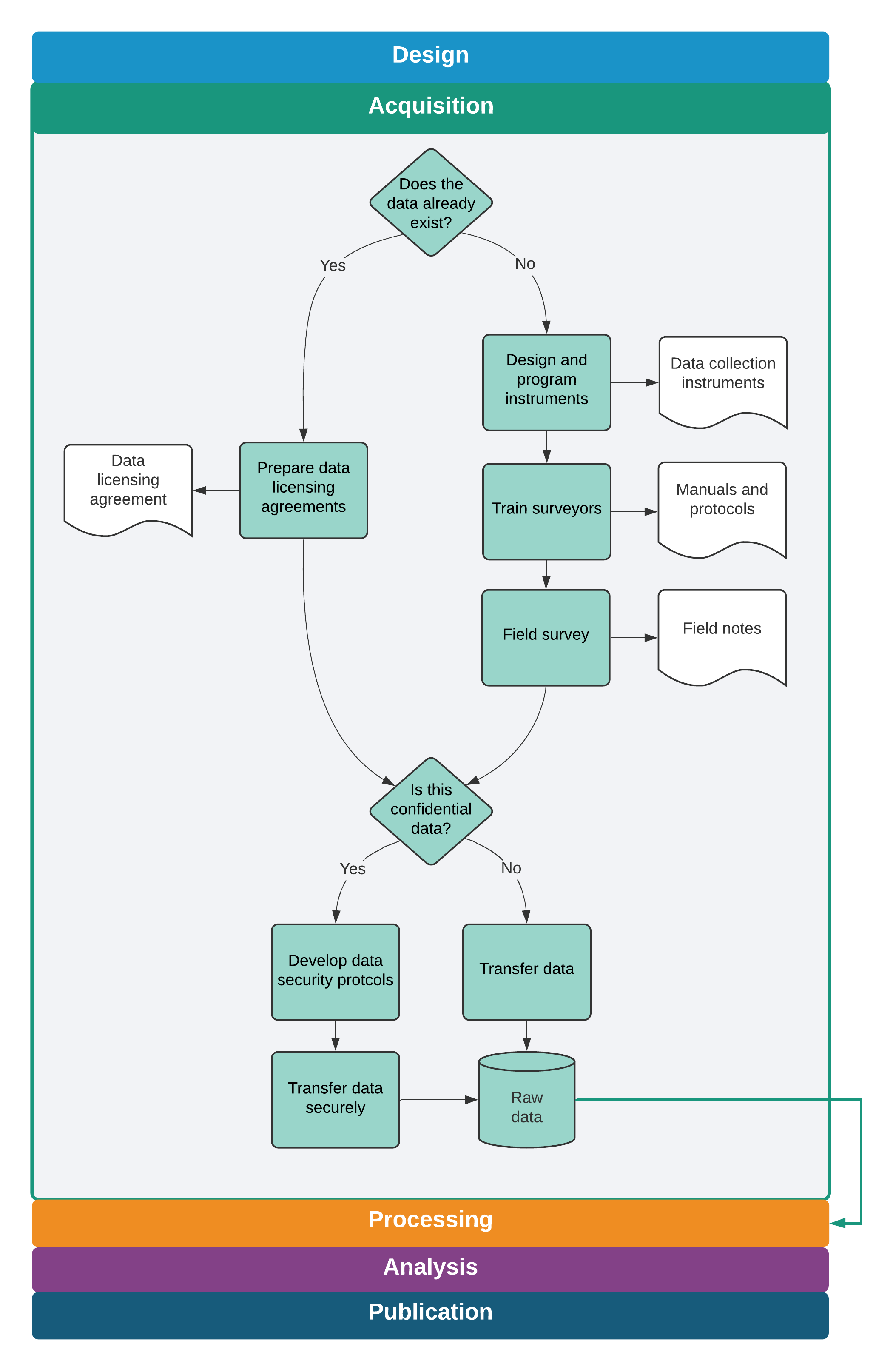
This chapter provided a road map to the acquisition of original data. It outlined guidelines for ensuring that the team has effective ownership or licensing of data that were obtained or collected and for determining how to make those materials available in the future. It also provided an extensive guide for one of the most common—and challenging—methods of data collection: primary electronic surveys. Finally, it emphasized the secure handling of this potentially sensitive information, providing a range of tools and a complete workflow for transferring and storing data securely at all times. Once original data are completely transferred, securely stored, and backed up, the data acquisition stage is complete, as summarized in figure 4.1. This is when the heavy lifting with statistical software starts. Before analyzing the data and answering the project’s research questions, it is necessary to check the quality of the data acquired, make sure that the right information is in hand and in the right format, and prepare the information for analysis. This process, called data cleaning and processing, is described in the next chapter.
Data ownership is the assignment of rights and privileges over data sets, including control over who may access, possess, copy, use, distribute, or publish data or products created from the data. For more details, see the DIME Wiki at https://dimewiki.worldbank.org/Data_Ownership.↩︎
Derivatives of data are new data points, new data sets, or outputs such as indicators, aggregates, visualizations, and other research products created from the original data.↩︎
An institutional review board (IRB) is an institutional body formally responsible for ensuring that research under its oversight meets minimum ethical standards. For more details, see the DIME Wiki at https://dimewiki.worldbank.org/IRB_Approval.↩︎
Data licensing is the process of formally granting rights and privileges over data sets to people who are not the owner of the data. For more details, see the DIME Wiki at https://dimewiki.worldbank.org/Data_License_Agreement.↩︎
Statistical disclosure risk is the likelihood of revealing information that can be used to associate data points with individual research participants, especially through indirect identifiers. For more details, see the DIME Wiki at https://dimewiki.worldbank.org/De-identification.↩︎
Questionnaire design is the process of creating a survey instrument, typically for data collection with human subjects. For details and best practices, see the DIME Wiki at https://dimewiki.worldbank.org/Questionnaire_Design.↩︎
Computer-assisted personal interviews (CAPIs) are interviews that use a survey instrument programmed on a tablet, computer, or mobile phone using specialized survey software. For more details, see the DIME Wiki at https://dimewiki.worldbank.org/Computer-Assisted_Personal_Interviews_(CAPI). For CAPI questionnaire programming resources, see the DIME Wiki at https://dimewiki.worldbank.org/Questionnaire_Programming.↩︎
A theory of change is a theoretical structure for conceptualizing how interventions or changes in environment might affect behavior or outcomes, including intermediate concepts, impacts, and processes. For more details, see the DIME Wiki at https://dimewiki.worldbank.org/Theory_of_Change.↩︎
Research design is the process of planning a scientific study so that data can be generated, collected, and used to estimate specific parameters accurately in the population of interest. For more details, see the DIME Wiki at https://dimewiki.worldbank.org/Experimental_Methods and https://dimewiki.worldbank.org/Quasi-Experimental_Methods.↩︎
A preanalysis plan is a document containing extensive details about a study’s analytical approach, which is archived or published using a third-party repository in advance of data acquisition. For more details, see the DIME Wiki at https://dimewiki.worldbank.org/Preanalysis_Plan.↩︎
A survey pilot is intended to test the theoretical and practical performance of an intended data collection instrument. For more details on how to plan, prepare for, and implement a survey pilot, see the DIME Wiki at https://dimewiki.worldbank.org/Survey_Pilot.↩︎
Coded-response options are responses to questions that require respondents to select from a list of choices, corresponding to underlying numerical response codes.↩︎
Open-ended questions are responses to questions that do not impose any structure on the response, typically recorded as free-flowing text.↩︎
A Likert scale is an ordered selection of choices indicating the respondent’s level of agreement or disagreement with a proposed statement.↩︎
ietestformis a Stata command to test for common errors andStatabest practices in electronic survey forms based on Open Data Kit (ODK), thereby ensuring that data are easily managed. It is part of theiefieldkitpackage. For more details, see the DIME Wiki at https://dimewiki.worldbank.org/ietestform.↩︎Data quality assurance checks or simply data quality checks are the set of processes put in place to detect incorrect data points due to survey programming errors, data entry mistakes, misrepresentation, and other issues. For more details, see the DIME Wiki at https://dimewiki.worldbank.org/Monitoring_Data_Quality.↩︎
A data quality assurance plan is the outline of tasks and responsibilities for ensuring that data collected in the field are accurate. For more details, see the DIME Wiki at https://dimewiki.worldbank.org/Data_Quality_Assurance_Plan.↩︎
High-frequency data quality checks (HFCs) are data quality checks run in real time during data collection so that any issues can be addressed while the data collection is still ongoing. For more details, see the DIME Wiki at https://dimewiki.worldbank.org/High_Frequency_Checks.↩︎
Back-checks are revisits to already interviewed respondents, in which the interviewer asks a subset of the survey questions a second time to audit survey accuracy. For more details, see the DIME Wiki at https://dimewiki.worldbank.org/Back_Checks.↩︎
Personally identifying information (PII) is any piece or set of information that can be linked to the identity of a specific individual. For more details, see the DIME Wiki at https://dimewiki.worldbank.org/Personally_Identifiable_Information_(PII) and pillar 4 of the DIME Research Standards at https://github.com/worldbank/dime-standards.↩︎
Encryption is a process of systematically masking the underlying information contained in digital files. This process ensures that file contents are unreadable even if laptops are stolen, databases are hacked, or any other type of access is obtained which gives unauthorized people access to the encrypted files. For more about encryption methods, see the DIME Wiki at https://dimewiki.worldbank.org/Encryption.↩︎