Geoprocessing Pipeline#
This document describes the general processing steps that have been applied to LSMS-ISA surveys since 2010. It also captures changes that have been made to the procedures and identifies points where survey-specific considerations come into play. A final section lists issues that could benefit from more research or re-evaluation.
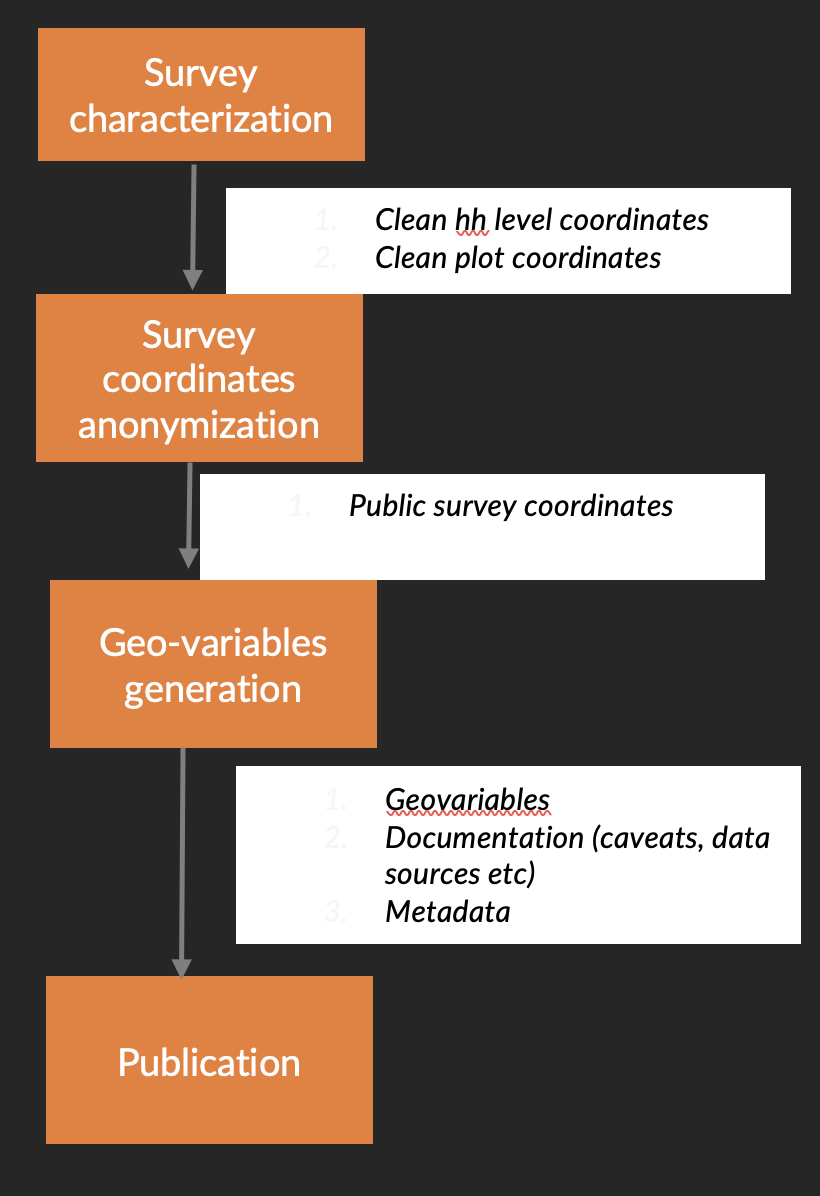
Fig. 1 Overview of the geo-enhancement pipeline#
add table of LSMS-ISA waves already processed?
Gather survey-specific information#
Surveys that are part of the LSMS-ISA program are longitudinal, with an original sample of households that is followed over a number of waves. Individuals that split-off and form new households and households that move may be followed in successive waves. The intended interval between waves is also survey-specific. At some point a partial or complete refresh of the sample is done in order to maintain population representativeness. The structure (one or more visits) varies across surveys, and there may be more than one reference agricultural season captured in a wave. These basic survey characteristics are needed for the data processing; to interpret results of common GPS checks, modify existing or create new checks, produce anonymized coordinates and generate spatial variables that are specific to survey season.
The main descriptive information is generally captured in the Basic Information Document (BID). If the survey has not already been released to the public then this document may not be available and the details will be obtained from the survey team. At a minimum, the following information is collected:
What is the reference agricultural season(s) or fieldwork timeline (in dates)?
What is the grouping variable that captures sampling cluster?
What level locality variables are to be released in public microdata?
Are locality variables included in the file with coordinates?
Is this part of a panel?
Are there new EAs that were not part of baseline?
Were anonymized coordinates released in earlier waves?
What is the link to household (same or parent) in prior waves?
What is the grouping variable that captures the original sampling cluster?
What is the grouping variable that reflects current status (ie for movers in successive panel waves this should not be baseline EA)?
Were households tracked? If so, what is the expected number of movers?
Were split offs tracked? If so, what is the link to parent household?
Were any coordinates (plot or household) subject to manual data entry (transcribed from handheld device) or possibly captured at a different location than the interview.
Review coordinates#
With the adoption of the Survey Solutions CAPI program, the locations of households and agricultural fields are captured by GPS-enabled tablet (although some surveys have continued to use hand-held GPS to record field locations as waypoints or field boundaries as tracks). Automatic capture eliminates most sources of data-entry error but it is worth noting that the interview document can be modified after the visit, recording a location that is not necessarily related to the household. The coordinates are provided by the survey team sometime after fieldwork is completed, usually in stata format as a subset of the household or plot rosters, by email or through shared onedrive location.
The purpose of coordinate review is to identify any anomalous records, locations that deviate from expected patterns, and determine how they should be treated. Examples might include very large distance between a plot and the related household, large household distance to EA average location, discrepancy with respect to locality variables in the microdata. Presence of these anomalies is usually minimal in a baseline survey but should still be checked.
Common steps for household coordinate review of a baseline or cross-sectional survey include:
Use grouping variable that represents sample cluster (for example enumeration area id) to calculate an average EA-level location.
Calculate household distance to EA average. The typical dispersion of households is < 2km around a centerpoint, but in sparsely populated rural areas this can exceed 5km. Extreme exceptions should be checked against any tracking information the survey team may have.
Recalculate cluster average after excluding confirmed movers or distant households. This EA average is the input to coordinate anonymization for non-movers.
Acquire spatial dataset of administrative units that correspond to the sample frame. Create a lookup table that links household records to spatial features by locality name or code (accounting for spelling differences and changes). Calculate distance to administrative unit of record. This is preferable to spatial join because it captures proximity to boundary and some tolerance (1km) can be applied to suppress mismatches due to boundary precision.
Additional steps for household coordinate review of successive wave of panel survey:
Identify link to parent or same household in all prior waves and calculate distance to each. We do not generate a second anonymized coordinate for a given ‘location’ because it would allow for intersection and reduction of anonymizing region. Previously released anonymized coordinates should be carried forward in successive waves if the current location is less than 5km from any prior wave.
Identify link to baseline EA average, and calculate distance. The EA location is imported from baseline year. It should not be re-calculated from current wave because this can include distance movers resulting in a distorted average. If distance is less than 5km then anonymized baseline EA offset is used in public file.
Identify records with missing GPS and discuss with survey team whether these records can be processed with either prior wave location or baseline EA average. Coordinate filling may also be possible from other within-wave visit.
Results of the distance to administrative unit of record check often identifies movers where the locality variables do not reflect current location. These can be shared with survey team to determine whether locality variables should be updated in microdata, but most often is just used as a diagnostic.
Records identified as distance movers are input to anonymization at household level.
See this sample coordinate review script
Apply anonymization and disclosure risk assessment#
The coordinate anonymization is based on aggregation as well as perturbation, following the DHS method where a random offset within a fixed range is applied to the cluster or EA average location. The anonymized coordinates are produced using a custom ArcGIS Toolbox ‘measure_dhs_tools.tbx’, specifically the script pointdisplacement.py. This version of the toolbox was shared by the DHS Program GIS coordinator in August 2013. The code was later published in DHS Spatial Analysis Reports SAR7 (python) and SAR8 (R). These files are in the onedrive folder DHS_anonymization.
Inputs to the tool are 1) shapefile of EA average location (for non-movers and local) and household level for distance movers, including urban-rural classes an attribute, and 2) administrative unit shapefile corresponding to lowest level locality to be released in the public microdata.
For LSMS-ISA the following parameters are used:
Urban/Rural mode=T
Max urban distance = 2km
Max rural distance = 5km for 90%, 10km for 10% (modified in the script)
Administrative level constraint = varies across surveys
Assess risk of disclosure#
The survey datasets include locality variables, region or district or other place name which can be easily linked to spatial features. The provision of anonymized coordinates allows for spatial refinement, or reduction, of these areas, increasing the spatial disclosure risk. Since 2018, a very simplistic measure of this risk has been computed based on the characteristics of the anonymizing region within which the survey site is known to be contained (buffer of anonymized coordinate using maximum offset). The number of EAs, number of named places/villages and population count from multiple gridded sources have been used, depending on the availability, quality and completeness of reference datasets for the country. Locations containing less than 3 EAs, 3 villages and 500 total population have very high disclosure risk.
Assemble spatial data for geovariables#
Spatial variables add value to survey datasets, supporting standardization of key variables and facilitating access to contextual information. The LSMS-ISA distributes, for each wave, a core set of cross-country comparable geospatial variables that are intended to provide some understanding of how geophysical characteristics vary at the landscape level. The variables, listed in Table 1, capture information about the local infrastructure and resource endowment and constraints, as well as some time-variant indicators that characterize the survey agricultural season with respect to normal growing conditions for the location. Due to the use of anonymized EA-level coordinates for integration, the variables are more location-specific than administrative level summary statistics.
ID |
Theme |
Variable |
|---|---|---|
1 |
Distance |
Plot distance to household, Household to nearest main road,market, border post, Household to headquarters of district of residence,Household to nearest city or town with 20,000+ |
2 |
Climatology |
Annual mean temperature & precipitation, Mean temperature & precipitation of wettest quarter Precipitation of wettest month. |
3 |
Landscape |
Majority landcover class, agro-ecological zone, Density of agriculture, Population density. |
4 |
Soil & Terrain |
Elevation, slope, roughness, topographic wetness index |
5 |
Rainfall (TS) |
Survey year annual rainfall, Survey year wettest quarter rainfall, survey year timing of start of wettest quarter |
6 |
Phenology (TS) |
Average total change in greenness within primary ag season,Average timing of onset of greenness increase& decrease,Average EVI value at peak of greenness,Total change in greenness in survey year,Timing of onset of greenness increase & decrease in survey year,Maximum EVI value in survey year. |
Using local archive for geovariable calculation. We have been hesitant to use api access with raw coordinates due to confidentiality issues, however this might be a more efficient approach for anonymized coordinates
Update select geospatial layers in existing archive as needed for refreshed panel
Note that for non-movers most variables are static across waves.
Update frequency
Change in reference data over time.
Generate geovariables#
2 levels: household and plot
household#
Initially derived by unmodified household coordinates. Changed to using the anonymized coordinates in 2018. This step was adopted after the first waves were released and some assessment of disclosure risk associated with the use of actual locations revealed high potential for reidentification of communities. Even with moderate resolution datasets and variable treatment (rounding, ranging), high dimensionality leads to spatial refinement/reduction of the anonymizing region
Plot#
Current small set of variables derived from higher spatial resolution datasets using unmodified plot GPS.
Sample scripts for variable extraction are:
pub_geovars_distance_IHS5.R
pub_geovars_raster_IHS5.R,
pub_geovars_ARC2_IHS5.R
pub_geovars_NDVI_IS5.R
pub_plot_IHS5.R
Common reference spatial datasets are in onedrive folder spatial_data. Survey-specific datasets are in a folder for each country/wave.
Prepare data for dissemination#
Anonymized coordinates that violate minimum criteria in the results of spatial disclosure risk assessment are treated before public release. For these locations the anonymized coordinates are suppressed or replaced by administrative unit centroids, although the geovariables may still be included in the public dataset.
Public data files are provided in stata format with descriptive labels. There is a base do file that is used for each wave, to import csv files populate labels and standardize names. There is also a section of the BID that describes geovariables. This includes a detailed table with description of each variable, source, reference time period, spatial resolution and link to reference spatial dataset where possible. The BID should also provide details of the anonymization method and mention of any additional treatment applied (such as suppression or
Other issues#
Strengthen spatial disclosure risk assessment. Acquire datasets that are more comprehensive and accurate, allowing for greater confidence in the assessment.
Explore alternatives for treatment of locations with high spatial disclosure risk. Iterate within modification procedure?
Look at combined spatial and non-spatial disclosure risk.
Expand variable list
Make use of api access to data sources where possible, in place of local archive
Produce scientific-use datasets with procedures for granting access