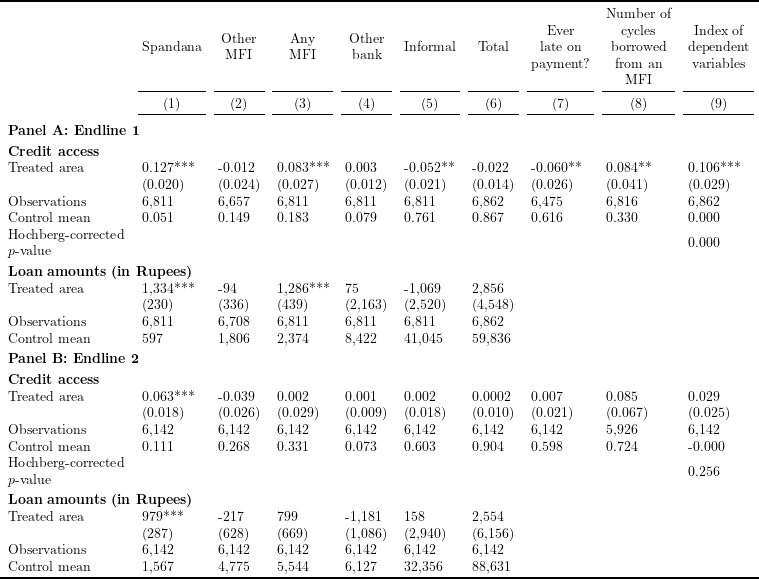
Table 2 in Banerjee et al. (2015), “The Mircle of Microfinance? Evidence from a Randomized Evaluation”
To read the created .tex file, the following \(\LaTeX\) packages are required:
- float
- pdflscape
- booktabs
- multicol
- makecell
# Install and load packages ---------------
packages <- c(
"tidyverse",
"haven",
"lfe",
"stargazer",
"broom",
"kableExtra",
"XML",
"magrittr"
)
pacman::p_load(packages, character.only = TRUE, install = TRUE)
# Load an example dataset ---------------
data_endline <- read_dta("Banerjee2015_replication/2013-0533_data_endlines1and2.dta")Table 2
# outcome variables
area_controls <- c(
"area_pop_base", "area_debt_total_base", "area_business_total_base",
"area_exp_pc_mean_base", "area_literate_head_base", "area_literate_base"
)
outcome_el1_credit <- c(
"spandana_1", "othermfi_1", "anymfi_1", "anybank_1", "anyinformal_1",
"anyloan_1", "everlate_1", "mfi_loan_cycles_1", "credit_index_1"
)
outcome_el1_amt <- c(
"spandana_amt_1", "othermfi_amt_1", "anymfi_amt_1",
"bank_amt_1", "informal_amt_1", "anyloan_amt_1"
)
outcome_el2_credit <- c(
"spandana_2", "othermfi_2", "anymfi_2", "anybank_2", "anyinformal_2",
"anyloan_2", "everlate_2", "mfi_loan_cycles_2", "credit_index_2"
)
outcome_el2_amt <- c(
"spandana_amt_2", "othermfi_amt_2", "anymfi_amt_2",
"bank_amt_2", "informal_amt_2", "anyloan_amt_2"
)
outcome_index_el1 <- c(
"credit_index_1", "biz_index_all_1", "biz_index_old_1",
"biz_index_new_1", "income_index_1", "labor_index_1",
"total_exp_mo_pc_1", "social_index_1"
)
outcome_index_el2 <- c(
"credit_index_2", "biz_index_all_2", "biz_index_old_2",
"income_index_2", "labor_index_2",
"total_exp_mo_pc_2", "social_index_2"
)# function for regressions with lfe::felm
reg_func <- function(varlist, weight, data, area_controls) {
tibble(
model = map(
varlist,
function(x) felm(
formula(
paste0(
x, " ~ ", paste0(c("treatment", area_controls), collapse = " + "),
" | 0 | 0 | areaid"
)
),
data = data,
weights = weight
)
)
)
}
# Hockberg-corrected p-values
res_index_el1 <- reg_func(outcome_index_el1, data_endline$w1, data_endline, area_controls)
pval_index_el1 <- map_dbl(
res_index_el1$model,
function(x) waldtest(x, "treatment")["p.F"]
)
# (correct way to calculate Hockberg-corrected p-values is
# p.adjust(pval_index_el1)
# or
# (pval_index_el1 * (length(pval_index_el1) + 1 - rank(pval_index_el1))),
# but to replicate the original table, we follow the calculation method in the original code
# )
adj_pval_index_el1 <- (pval_index_el1 * (length(pval_index_el1) + 1 - rank(- pval_index_el1)))
adj_pval_index_el1_str <- ifelse(
adj_pval_index_el1 > 1, "> 0.999",
formatC(adj_pval_index_el1, digits = 3, format = "f")
)
res_index_el2 <- reg_func(outcome_index_el2, data_endline$w2, data_endline, area_controls)
pval_index_el2 <- map_dbl(
res_index_el2$model,
function(x) waldtest(x, "treatment")["p.F"]
)
adj_pval_index_el2 <- (pval_index_el2 * (length(pval_index_el2) + 1 - rank(- pval_index_el2)))
adj_pval_index_el2_str <- ifelse(
adj_pval_index_el2 > 1, "> 0.999",
formatC(adj_pval_index_el2, digits = 3, format = "f")
)# function to create a panel of regression results
tab2_reg_func <- function(
varlist, weight, data, digits, area_controls, outfile
) {
res_reg <- reg_func(varlist, weight, data, area_controls)
control_mean <- map2_chr(
res_reg$model, varlist,
function(x, y) ifelse(
colMeans((model.frame(x) %>% filter(treatment == 0))[y]) > 1,
formatC(
colMeans((model.frame(x) %>% filter(treatment == 0))[y]),
digits = 0, format = "f", big.mark = ","
),
formatC(
colMeans((model.frame(x) %>% filter(treatment == 0))[y]),
digits = 3, format = "f", big.mark = ","
)
)
)
res_reg %>%
pull(model) %>%
stargazer(
title = "Replication of Table 2 in Banerjee et al. (2015)",
keep = c("treatment"),
no.space = TRUE,
type = "html",
out = file.path("html", outfile),
covariate.labels = c(
"Treated area"
),
add.lines = list(
c("Control mean", control_mean)
),
omit.stat = c("adj.rsq", "ser", "rsq"),
table.layout = "=#c-t-sa-n",
digits = digits
)
}
tab2_reg_func(
outcome_el1_credit, data_endline$w1, data_endline,
3, area_controls, "Banerjee_table2Acredit.html"
)
tab2_reg_func(
outcome_el1_amt, data_endline$w1, data_endline,
0, area_controls, "Banerjee_table2Aamt.html"
)
tab2_reg_func(
outcome_el2_credit, data_endline$w2, data_endline,
3, area_controls, "Banerjee_table2Bcredit.html"
)
tab2_reg_func(
outcome_el2_amt, data_endline$w2, data_endline,
0, area_controls, "Banerjee_table2Bamt.html"
)
# function to read .html data and keep as matrix
tab2_read_html <- function(filename) {
readHTMLTable(file.path("html", filename)) %>%
.$`Replication of Table 2 in Banerjee et al. (2015)` %>%
drop_na() %>%
filter(!apply(., 1, function(x) all(x == ""))) %>%
slice(-c(1)) %>%
as.matrix() %>%
set_colnames(NULL)
}
tab2Acredit <- tab2_read_html("Banerjee_table2Acredit.html")
tab2Aamt <- tab2_read_html("Banerjee_table2Aamt.html") %>%
cbind("", "", "")
tab2Bcredit <- tab2_read_html("Banerjee_table2Bcredit.html")
tab2Bamt <- tab2_read_html("Banerjee_table2Bamt.html") %>%
cbind("", "", "")
# combine panels and save as .tex file
rbind(
tab2Acredit,
c("Hochberg-corrected\n$p$-value", rep("", 8), adj_pval_index_el1_str[1]),
tab2Aamt,
tab2Bcredit,
c("Hochberg-corrected\n$p$-value", rep("", 8), adj_pval_index_el2_str[1]),
tab2Bamt
) %>%
as_tibble() %>%
mutate_all(linebreak, align = "l") %>%
as.matrix() %>%
set_colnames(NULL) %>%
kable("latex", booktabs = TRUE, escape = FALSE) %>%
kable_styling(latex_options = "scale_down") %>%
add_header_above(c("", paste0("(", seq(9), ")"))) %>%
add_header_above(c(
"", "Spandana", "Other\nMFI", "Any\nMFI", "Other\nbank",
"Informal", "Total", "Ever\nlate on\npayment?",
"Number of\ncycles\nborrowed\nfrom an\nMFI",
"Index of\ndependent\nvariables"
)) %>%
pack_rows(index = c(
"Panel A: Endline 1" = 0,
"Credit access" = 5,
"Loan amounts (in Rupees)" = 4,
"Panel B: Endline 2" = 0,
"Credit access" = 5,
"Loan amounts (in Rupees)" = 4
),
indent = FALSE) %>%
save_kable("tex/Banerjee_table2_replicate.tex")