Chapter 2 Features of a modern data dissemination platform
In the introductory section of this Guide, we proposed that modern data dissemination platforms should be modeled after the most successful e-commerce platforms. These platforms are optimized to serve both buyers (in our context, the data users) and sellers (in our context, the data providers) in the most efficient manner. Internet search engines, and in particular the way they exploit the capabilities of generative artificial intelligence, are also a useful source of inspiration for the design of data catalogs. In this chapter, we outline features that a modern online data catalog should incorporate to adhere to these models.
We provide recommendations for developing data catalogs that encompass lexical search and semantic search, filtering, advanced search functionality, interactive user interfaces, and the capability to operate as useful recommender systems. We approach the topic from three distinct perspectives: the viewpoint of data users, who represent a highly diverse community with varying needs, preferences, expectations, and capabilities; the standpoint of data suppliers, who either publish their data or delegate the task to a data library; and the perspective of catalog administrators, responsible for curating and disseminating data in a responsible, effective, and efficient manner while optimizing both user and supplier satisfaction.
The creation of a data dissemination platform is a collaborative endeavor, engaging data curators, user experience (UX) experts, user interface (UI) designers, search and systems engineers, and subject matter specialists with a profound understanding of both the data and the users’ requirements and preferences. Inclusive in this development process should be the active participation of the users, allowing them to provide feedback that directly influences the system’s design.
The set of features we describe below are proposed for a large data catalog, developed and maintained by a well-resourced organization. Not all features would be appropriate for a small catalog or for a catalog maintained by an organization facing technical and other constraints. In such situations, semantic search capability and the implementation of features that require the implementation of machine learning of generative artificial intelligence may not be recommended.
2.1 Features for data users
To foster a positive user experience, online data catalogs must feature an intuitive and efficient interface, enabling users to effortlessly access the most relevant datasets. Emphasizing simplicity and relevance is crucial to meet user expectations effectively. Additionally, a data dissemination platform should be made accessible without discrimination. Aligning with the Web Content Accessibility Guidelines (WCAG) international standard, which provides principles and recommendations for accessibility to people with disabilities, can enhance the design of data catalogs, delivering a seamless and user-friendly experience akin to popular internet search engines and e-commerce platforms.
Users of a data catalog typically desire to search, filter, browse, and possibly sort the available assets. Below, we outline how these features can be designed to provide a user-friendly experience. Additionally, we propose other useful features enabled by artificial intelligence (AI).
As AI and machine learning solutions progress, these search engines can go beyond delivering a ranked list of results. In certain scenarios, particularly when a user’s query allows, the search algorithm can generate a more direct and informative response. This might take the form of a conversational answer synthesized through generative AI or the presentation of structured data grids and visualizations that directly address the query. Implementing such capabilities effectively requires a system with a level of intelligence to discern the appropriate response strategy. This involves parsing the intricacies of the query, recognizing patterns, and making informed decisions on whether to provide a direct answer or return a ranked list of resources conventionally. The integration of advanced AI and ML technologies with search engines in data catalogs marks a significant evolution, empowering users with more nuanced and contextually relevant information retrieval experiences.
2.1.1 Search
Search engines implemented in data catalogs can be categorized as either lexical or semantic, or they may seamlessly integrate elements of both. A lexical search, also referred to as a “keyword search” or “full-text search”, operates by matching literal terms from a user query to the search engine’s index, subsequently returning datasets whose indexed metadata includes the specified terms. On the other hand, a semantic search strives to pinpoint datasets with metadata that bears semantic resemblance to the query. Ideally, a comprehensive data catalog would incorporate both lexical and semantic search engines, seamlessly blended into a unified search tool. However, the integration of semantic search functionality presents a complexity in implementation.
Semantic search leverages advanced techniques like embeddings, vector indexing, and similarity measures to enhance the precision and relevance of search results by capturing the semantic meaning of user queries and dataset content. The process typically involves converting words or phrases into high-dimensional vectors using embedding models. Embeddings are representations of words or phrases in a continuous vector space, where semantically similar terms are positioned closer to each other.
Vector indexing in specialized vector databases is a key aspect of semantic search. Vector databases are optimized for storing and querying high-dimensional vectors efficiently. They enable the indexing of embeddings associated with both user queries and catalog resources, allowing for fast and accurate similarity searches. Cosine similarity is a common measure used in semantic search to quantify the similarity between vectors. In a vector space, the cosine of the angle between two vectors is calculated, with a higher cosine indicating greater similarity. This measure is instrumental in ranking and retrieving datasets based on their semantic relevance to a user’s query.
To facilitate the implementation of semantic search, APIs play a crucial role. APIs for generating embeddings streamline the process by providing access to pre-trained models or embedding services. These APIs take care of the complex task of converting textual data into meaningful embeddings, saving time and resources for developers. Additionally, APIs for search engines allow the integration of semantic search capabilities seamlessly, enabling the retrieval of relevant results based on semantic similarity.
In a search engine, semantic search is often combined with lexical search to offer a comprehensive and effective discovery system. Lexical search involves matching literal terms in a user query to the search engine’s index, while semantic search focuses on identifying datasets with semantically similar metadata. Combining these approaches ensures a balanced and robust search system, catering to a wide range of user preferences and query styles.
2.1.1.1 Search box
In a data catalog, the primary means of searching for data is typically through a single, intuitive search box. Recognizing the diversity in users’ search capabilities, the search engine must be designed to accommodate a range of query inputs, acknowledging that not all users will craft perfect queries.
To enhance user experience and overcome potential spelling errors, the search engine may leverage advanced indexing tools such as Solr or ElasticSearch. Additionally, users should have the flexibility to input queries either through traditional keyboard entry or via audio commands.

Ensuring a nuanced understanding of user queries, the search engine should employ sophisticated processes, including automated query parsing and enhancement. This parsing mechanism extracts crucial information from the query, discerning factors such as the type of data under consideration, whether the query pertains to specific indicators within the catalog assets, references to geographic locations, time-related elements, and the suitability of a keyword search versus a semantic search. The system also endeavors to detect the language of the query and, if necessary, offers translation services.
A pivotal aspect of the search engine’s functionality lies in its ability to decipher the user’s intent and return results ranked by relevance. This demands an intricate analysis of the query, potentially leading to immediate answers. Depending on the nature of the query, the application must intelligently determines whether to present results in textual form, organize them in a data grid, or generate visualizations for a more comprehensive understanding. This multifaceted approach ensures that users can interact seamlessly with the data catalog, obtaining the most pertinent information in a manner that aligns with their preferences and requirements.
2.1.1.2 Document as a query
A search engine equipped with semantic search capabilities extends its user-friendly functionality by accommodating queries of varying lengths, including the innovative option for users to submit entire documents—whether in PDF or TXT format—as queries. Upon receiving a document query, the search engine initiates a sophisticated process wherein it meticulously analyzes the semantic content within the document. This involves transforming the document into an embedding vector, a compact representation capturing its semantic essence. Subsequently, the search engine adeptly identifies and retrieves the most relevant resources from the catalog, ensuring a nuanced and contextually rich response to the user’s document-based query.

2.1.1.3 Image as a query
A cutting-edge search engine, empowered with advanced image search capabilities, introduces an innovative dimension to user interaction by enabling the submission of images as queries. Users can seamlessly upload images in various formats, unlocking a novel means of exploration. Upon receiving an image query, the search engine embarks on a sophisticated journey, meticulously analyzing the visual content embedded in the image. Through intricate processes such as feature extraction and image embedding, the search engine translates the visual information into a compact and meaningful representation. Leveraging this representation, the search engine then identifies and retrieves the most pertinent resources from the catalog, delivering a tailored and visually aligned response to the user’s image-based query. This transformative capability enhances the search experience, allowing users to explore and discover relevant content through the lens of visual input.
2.1.1.4 Suggested queries
Modern search engines can enhance the user experience through the proactive generation of relevant and refined query suggestions. Going beyond mere processing of user queries, these advanced search engines employ sophisticated techniques to automatically propose alternative queries that are more useful and pertinent. This intelligent feature is often implemented by leveraging expansive graphs of related words, crafted by state-of-the-art Natural Language Processing (NLP) models. These graphs tap into the inherent semantic relationships between words, offering a comprehensive understanding of language nuances.
To implement dynamic query suggestions seamlessly, integration with an API becomes imperative. By dynamically linking a data catalog’s user interface with a machine learning model, such an API facilitates the retrieval of insightful keyword recommendations grounded in the intricate web of semantic connections identified by NLP models. Users benefit from a fluid and intuitive search experience as the search engine anticipates their needs and refines their queries in real-time. This proactive query suggestion mechanism reflects the evolving landscape of search technology, where the fusion of NLP and intelligent algorithms empowers users with not only accurate search results but also a collaborative and responsive search process.
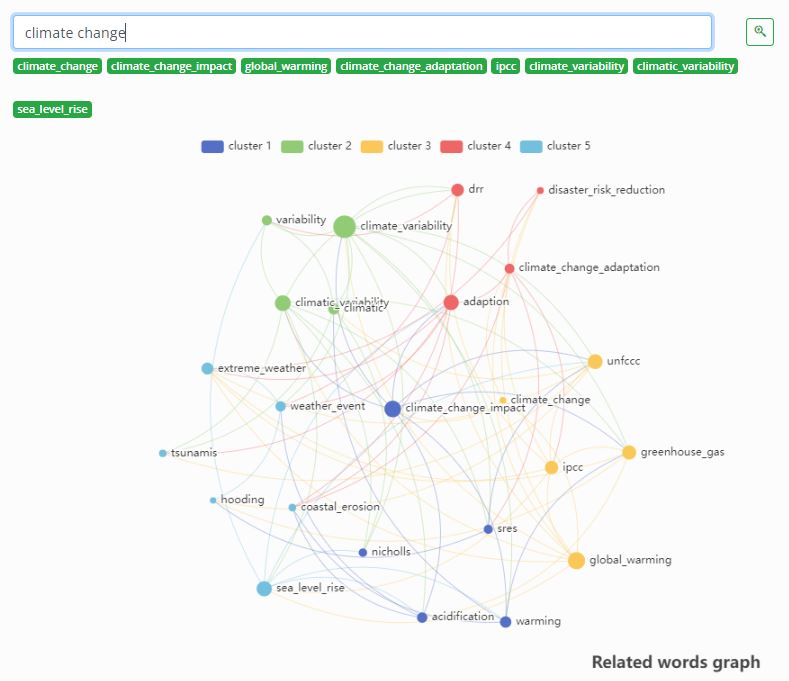
A search interface could retrieve such information via API and display it as follows:

2.1.1.5 Advanced search
Advanced search are enabled by structured metadata, i.e., by the use of metadata standards. Accessible through an intuitive user interface, an “advanced search” option provides users with a dynamic and interactive platform to specify their search criteria. Users can pinpoint their focus to distinct metadata fields, enabling a fine-grained exploration of datasets within the catalog. Furthermore, to cater to users familiar with syntax-based queries, the advanced search offers a syntax option, granting more adept users the flexibility to craft complex search queries using boolean operators. Whether through the user-friendly interface or the syntax option, the advanced search capability provides a comprehensive and tailored search experience. This feature not only acknowledges the diverse needs of users but also reflects the catalog’s ability to facilitating efficient and precise data discovery through the judicious use of structured metadata.

2.1.1.6 Geographic search
Geographic discoverability and searchability within data catalogs are critical components that cater to the diverse needs of users seeking information pertaining to specific geographic areas. Data catalogs routinely receive a substantial volume of queries centered around particular regions, whether at the country level, sub-national entities, or non-administrative geographic features like watersheds and oceans. In the context of data catalogs housing geographic datasets, it becomes imperative to offer specialized search tools that enhance the precision and relevance of spatial data discovery.
While metadata standards often allow the utilization of bounding boxes to specify geographic coverage, this method has inherent limitations that make it imperfect. Drawing a box on a map to define an area oversimplifies the complexity of geographical features, particularly when users are interested in irregular or non-standard shapes. To address this limitation, it is recommended to incorporate advanced geographic search tools that provide users with more nuanced ways to explore datasets based on their spatial characteristics.
Geographic indexing emerges as a powerful solution for datasets with explicit geographic content. The H3 index, known for its hierarchical hexagonal structure, proves to be a robust option. The hierarchical nature of the H3 index facilitates efficient aggregation and retrieval of data at various levels of granularity, offering an effective means to enhance the geographic discoverability of datasets within a catalog. By adopting geographic indexing, the catalog ensures that users can precisely identify and access datasets relevant to their spatial requirements.
Recognizing that many users rely on keyword searches to discover data, it is also essential to address the challenges associated with incomplete metadata coverage. For instance, a raster image of the Philippines obtained from satellite imagery may contain the country name in its metadata. Still, specific sub-national areas like “Iloilo” may not be explicitly mentioned. To overcome this limitation, a sophisticated search engine should implement intelligent query parsing. This involves detecting if a user query contains the name of a geographic area, automatically identifying the corresponding polygon of geographic coordinates. This process can be facilitated by leveraging APIs such as Nominatim. Subsequently, the search engine retrieves relevant resources in the catalog that cover the specified geographic area, underscoring the importance of geographically indexing datasets to enable accurate and comprehensive results.
This integrated approach ensures that users can seamlessly navigate and explore geographic datasets within the catalog, whether through advanced search tools, geographic indexing, or intelligent keyword parsing, thereby fostering a robust and user-centric data discovery experience.

Example of use of Nominatim: The Nominatim application shows the polygon boundary for the search query “Iloilo City” automatically provided by the API.

The search API endpoint of Nominatim returns this JSON data which can be processed to generate search cell(s).

2.1.1.7 Results ranking
A search engine must not only identify relevant datasets but also present them in an ordered list based on their level of relevance. The ranking of results directly influences users’ ability to quickly find pertinent information, with the most relevant outcomes prominently positioned at the top. If users do not encounter relevance in the initial results, there’s a risk of them seeking data from alternative sources, emphasizing the critical role of effective result ranking in user satisfaction and retention.
Achieving optimal result ranking hinges on the careful consideration of both the content and structure of metadata. Relevance engineering plays a pivotal role in this process, requiring fine-tuning of advanced search tools such as Solr or ElasticSearch. This is a crucial step in ensuring that the search engine not only identifies relevant datasets but also presents them in a manner that aligns with users’ expectations.
Optimizing keyword-based searches is integral to effective result ranking. While out-of-the-box solutions like those provided by SQL databases may fall short, advanced indexing tools such as Solr and ElasticSearch offer robust mechanisms for enhancement. Structured metadata proves to be a key ally in this optimization effort, enabling the boosting of specific metadata elements. For instance, a query term found in the title holds greater weight than if found in notes, and results are ranked accordingly. Similarly, attributing more weight to a country name found in designated metadata elements like nation or reference country ensures that results align with the contextual relevance of the query.
Furthermore, advanced indexing tools provide additional functionalities, including grouping, sequencing, and proximity-based considerations, further refining the result ranking process. The boosting capabilities offered by tools like Solr and ElasticSearch empower search engines to adapt and align with the nuanced preferences of users, ultimately contributing to an enhanced and efficient data discovery experience.
For large data catalogs managed by well-resourced agencies, the exploration of machine learning solutions, particularly “learn-to-rank” techniques, offers an avenue for result ranking enhancement. This involves leveraging the expertise of data scientists to develop models that can intelligently weigh and prioritize results based on relevance, contributing to an improved and personalized user experience.
2.1.1.8 Saving and sharing results
Empowering users with the ability to save, export, and share their search queries within a data catalog search engine enhances the overall utility and collaborative potential of the platform. The option to save a search query for future re-use provides users with a convenient way to revisit and refine their information retrieval strategies. This is particularly beneficial for users engaging in recurrent or complex data exploration, allowing them to streamline their workflow and save time.
The capability to export search results is equally crucial, offering users the flexibility to analyze and manipulate the obtained data outside the confines of the search engine. Exported results, whether in the form of downloadable files or accessible URLs, enable seamless integration with external tools and applications for further analysis or visualization.
Sharing functionalities contribute to the collaborative aspect of data exploration. Enabling users to share both their saved queries and the results with others fosters knowledge exchange and collaboration within the user community. The option to share via social media platforms adds an additional layer of accessibility, allowing users to disseminate valuable insights to a broader audience and potentially connect with others who share similar interests or objectives.
In essence, the ability to save, export, and share search queries and results not only enhances the individual user experience by facilitating efficient workflow management but also promotes collaboration, knowledge-sharing, and community engagement within the data catalog ecosystem. This collaborative dimension contributes to the creation of a more dynamic and interactive user community, fostering a culture of shared insights and collective learning.
2.1.2 Filtering
The incorporation of filtering options, such as facets or other navigational tools, alongside a search engine within a data catalog is of paramount importance. While search engines excel at pinpointing specific items based on user queries, filtering options complement this functionality by enabling users to refine and explore the catalog comprehensively. These filters empower users to navigate through extensive datasets with precision, allowing them to narrow down results based on criteria such as data type, date range, or specific attributes. This not only streamlines the browsing experience for users seeking specific subsets of information but also facilitates a more nuanced exploration of the entire catalog. By offering both a powerful search engine and versatile filtering mechanisms, a data catalog ensures that users can efficiently uncover relevant data through tailored search queries or by dynamically refining their exploration of the complete catalog or search results.
2.1.2.1 Facets
Facets, also referred to as filters, play a crucial role in enhancing the usability of a data catalog by allowing users to refine their searches and navigate through datasets with precision. Structured metadata and controlled vocabularies form the backbone of these facets, providing a systematic framework for categorizing and organizing information. For example, in a data catalog featuring datasets from various countries, a “country” facet can serve as a powerful filter, enabling users to swiftly locate relevant datasets associated with specific geographic regions. The effectiveness of these filters hinges on metadata elements characterized by a limited number of categories and a predictable set of options, which is facilitated through the use of controlled vocabularies.
In the user interface (UI) of a data catalog, the visibility and accessibility of activated filters are paramount. UI design should prioritize making activated filters easily noticeable and providing a straightforward mechanism for deactivation, such as the use of filter “pills” that can be conveniently toggled on and off. This ensures that users have a transparent and intuitive means of managing their refined search criteria. Additionally, recognizing that certain metadata elements are inherently tied to specific data types, the integration of contextual facets within the catalog’s UI becomes essential. These contextual facets dynamically offer relevant filters based on the type of data being searched, further optimizing the user experience and facilitating efficient exploration of the catalog’s diverse datasets.
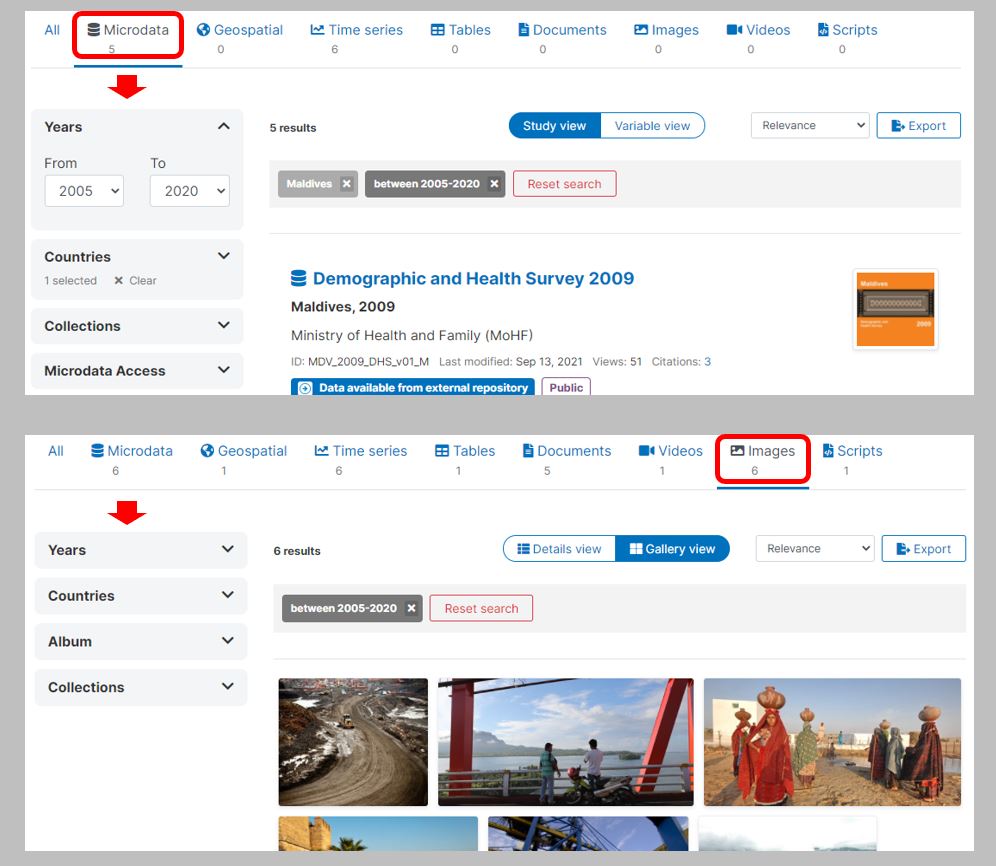
Tags and tag groups (which are available in all schemas we recommend) provide much flexibility to implement facets, as we showed in section 1.7.
2.1.2.2 Organizing entries by collection
Organizing data assets into virtual collections within catalogs significantly enhances users’ ability to navigate and discover relevant information efficiently. These collections, which can be structured thematically, geographically, by sponsor, producer, or any other relevant criteria, serve as intuitive groupings (and filters) that streamline the search process. For instance, datasets may be grouped by the origin of the data, geographic coverage, or thematic focus. The virtual nature of collections allows a single data asset to belong to multiple collections simultaneously, recognizing the multidimensional nature of datasets. Each collection must come with a brief descriptive overview, providing users with valuable context about the content it encompasses.
2.1.2.3 Organizing entries by data type
Organizing data assets within a data catalog by main data type facilitates user navigation and ensures that individuals can easily locate the specific information they seek. In a catalog encompassing diverse data types such as microdata, indicators, geographic datasets, documents, and more, offering a streamlined mechanism for users to filter and display query results by data type is paramount. This functionality accommodates the varied needs of users conducting searches with distinct objectives.
Consider a scenario where users are searching for “US population.” One user may be interested solely in obtaining the total population of the USA, while another might specifically seek the public use census microdata sample, and a third may be looking for a relevant publication. To cater to these diverse needs, presenting query results in type-specific tabs (with an “All” option) or providing a filter (facet) by type becomes instrumental. This approach empowers users to focus on the particular data types that align with their requirements, streamlining the information retrieval process.
By implementing such features, data catalogs not only enhance user experience but also cater to the varying capacities and expertise of users. For example, users without statistical analysis expertise may prefer to filter out microdata, focusing only on data types that align with their capabilities. This organization and filtering by data type contribute to a more personalized and user-centric service, ensuring that individuals can efficiently access and utilize the data most relevant to their specific needs and competencies.

2.1.2.4 Filtering by access type
Organizing data assets within a data catalog by mode of access and access policy also contributes to ensuring that users can easily identify and access datasets aligned with their specific needs, preferences, and compliance requirements. The mode of access, whether through bulk download, API, or other means, serves as a critical factor for users who may have distinct preferences or technical capabilities. For instance, some users might prefer bulk download options for offline analysis, while others may seek real-time access through APIs.
Equally important is the categorization of datasets based on access policies. Clear and transparent access policies, preferably articulated through a standard license and utilizing a controlled vocabulary, provide users with essential information regarding the type of access granted. This could include distinctions between open access, public use files, licensed access, or access within a secure data enclave. The use of controlled vocabulary enables the creation of a facet (filter) that allows users to refine their search based on specific access conditions.
Making access policies prominently visible in the data catalog is essential for user understanding and compliance. A standardized presentation, potentially through a facet, allows users to quickly filter datasets based on their preferred level of access and usage rights. Additionally, any specific access conditions, restrictions, or requirements should be clearly communicated to users to ensure transparency and adherence to relevant legal and ethical considerations. In this way, organizing data assets by mode of access and access policy not only simplifies the user’s navigation of the catalog but also contributes to a more informed and responsible use of the available datasets.
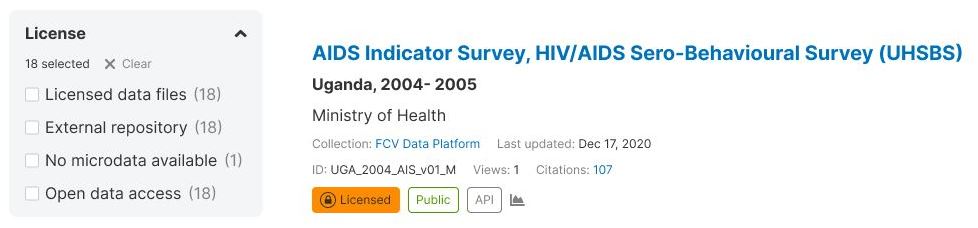
2.1.3 Browsing
Browsing a data catalog refers to the process of exploring and navigating through the catalog’s contents to discover relevant datasets or information. Unlike targeted searches that involve specific queries, browsing involves a more exploratory approach, allowing users to casually peruse the catalog’s offerings. It is akin to strolling through the aisles of a library or scanning the shelves of a bookstore to see what catches your interest.
In the context of a data catalog, browsing typically involves navigating through categories, collections, or filters that organize datasets based on thematic, geographic, or other criteria. Users might scroll through a list of datasets, explore collections related to specific topics, or filter results based on certain attributes. The goal is to serendipitously come across valuable data assets, discover new insights, or identify datasets that align with the user’s interests or project requirements.
Effective browsing in a data catalog often relies on well-organized metadata, clear categorization, and intuitive user interfaces. Browsing functionality can encompass various features such as filters, facets, and sorting options, enabling users to refine their exploration and focus on datasets that match their criteria. Ultimately, the browsing experience in a data catalog is designed to be user-friendly, encouraging users to efficiently explore and discover the wealth of information available within the catalog’s repository.
2.1.3.1 Providing core information in the listing page
Designing a data catalog with a concise and informative listing page, presented in the form of a card, is crucial for optimizing user experience and aiding efficient decision-making. This card format should encapsulate key details such as entry title, period, geographic coverage, producer, API availability, a brief description, and potentially a logo. By encapsulating these essential elements in a compact display, users can swiftly evaluate the relevance of a dataset without the need to navigate to a separate page.
The entry title serves as a focal point, providing a quick overview of the dataset’s main subject. Period and geographic coverage offer immediate insights into the temporal and spatial dimensions of the data. Knowing the producer lends credibility and context to the dataset, while information on API availability indicates the level of accessibility and functionality for technically inclined users. A concise description complements these details, offering a snapshot of the dataset’s purpose and content. Including a logo enhances visual recognition, especially for datasets associated with specific organizations or brands.
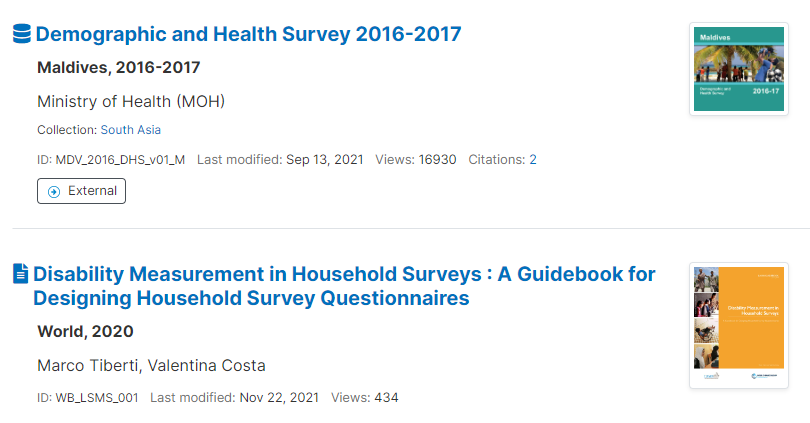
This streamlined presentation ensures that users can make informed decisions about exploring further details without the need to open multiple pages. The goal is to empower users with enough information upfront, streamlining their browsing experience and enabling efficient decision-making regarding the datasets most relevant to their needs. Ultimately, the catalog card functions as a powerful tool to engage users, providing a snapshot of critical information and enticing them to delve deeper into datasets that align with their specific interests and requirements.
2.1.3.2 Featured and most popular entries
Highlighting popular datasets or those strategically promoted by catalog administrators serves as a valuable guide for users seeking the most relevant and frequently accessed information. This feature streamlines the user experience by directing attention to datasets that have garnered widespread interest or are considered particularly valuable. It not only expedites the search process but also provides users with insights into what datasets are trending or widely utilized by their peers. Additionally, catalog administrators can leverage this feature to promote datasets that align with organizational goals, encouraging users to explore and utilize resources that are strategically significant.
2.1.3.3 Recent additions and history
Providing users with a list of the “latest additions” and maintaining a history of additions and modifications in a data catalog is highly useful for several reasons.
- Stay updated: The “latest additions” feature allows users to quickly identify and access the most recently added datasets. This is particularly valuable for users who want to stay up-to-date with the latest information or who are interested in newly available datasets that might be relevant to their work or research.
- Track changes: A history of additions and modifications provides transparency and accountability. Users can track changes made to datasets over time, including updates, revisions, or corrections. This history is crucial for maintaining data integrity and ensuring users are aware of any changes that may impact their use of the data.
- Version control: For datasets that undergo multiple versions or updates, a history log helps users understand the evolution of the data. This version control is essential for researchers, analysts, or anyone relying on specific versions of datasets for consistency and reproducibility in their work.
- Enhance trust: Transparency in the catalog’s modification history builds trust among users. Knowing when and how datasets have been added or modified contributes to the credibility of the catalog and the reliability of the data it contains.

2.1.3.4 Metadata display and formats
To make metadata easily accessible to users, it is important to display it in a convenient way. The display of metadata will vary depending on the data type being used, as each type uses a specific metadata schema. For online catalogs, style sheets can be utilized to control the appearance of the HTML pages.
In addition to being displayed in HTML format, metadata should be available as electronic files in JSON, XML, and potentially PDF format. Structured metadata provides greater control and flexibility to automatically generate JSON and XML files, as well as format and create PDF outputs. It is important that the JSON and XML files generated by the data catalog comply with the underlying metadata schema and are properly validated. This ensures that the metadata files can be easily and reliably reused and repurposed.
2.1.3.5 Variable-level comparison
This features is specific to microdata. E-commerce platforms commonly allow customers to compare products by displaying their pictures and descriptions side-by-side. Similarly, for data users, the ability to compare datasets can be valuable to evaluate the consistency or comparability of a variable or an indicator over time or across sources and countries. However, to implement this functionality, detailed and structured metadata at the variable level are necessary. These metadata standards, such as DDI and ISO 19110/19139, enable the implementation of this feature. In the example below, we show how a query for water returns not only a list of seven datasets, but also a list of variables in each dataset that match the query.
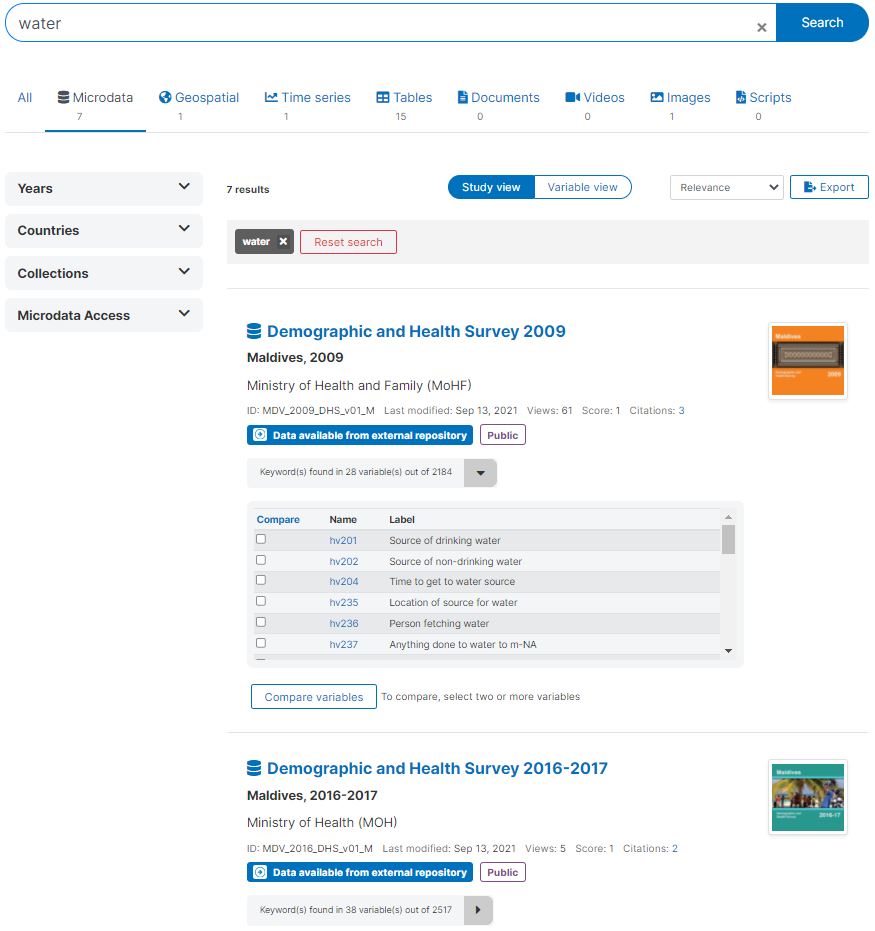
The variable view shows that a total of 90 variables match the searched keyword.
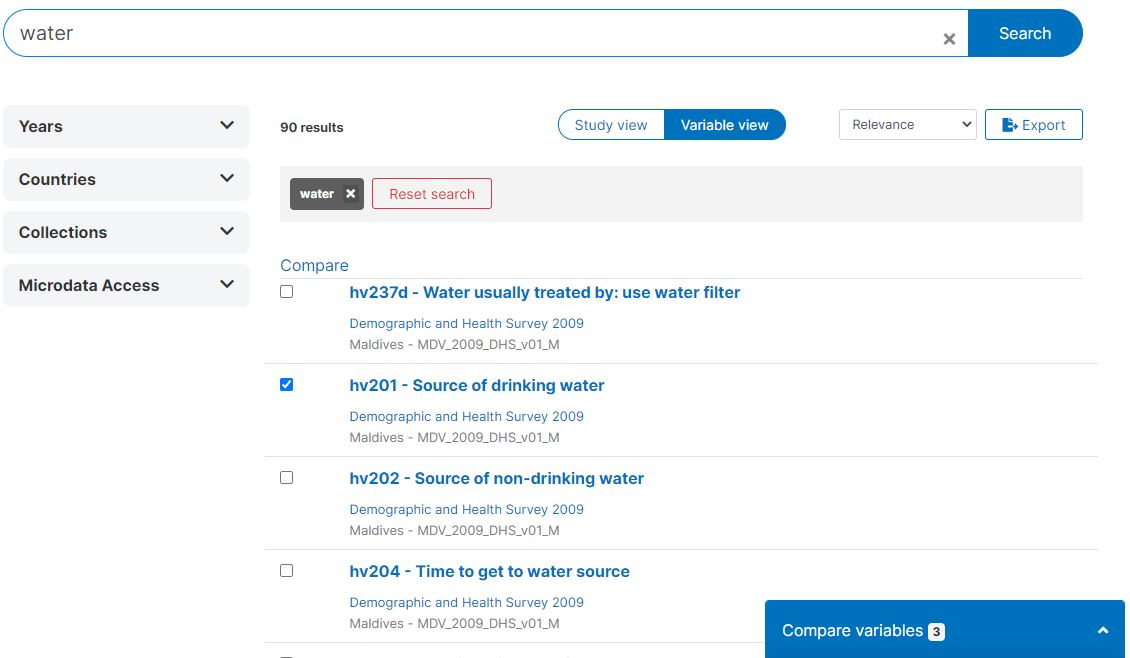
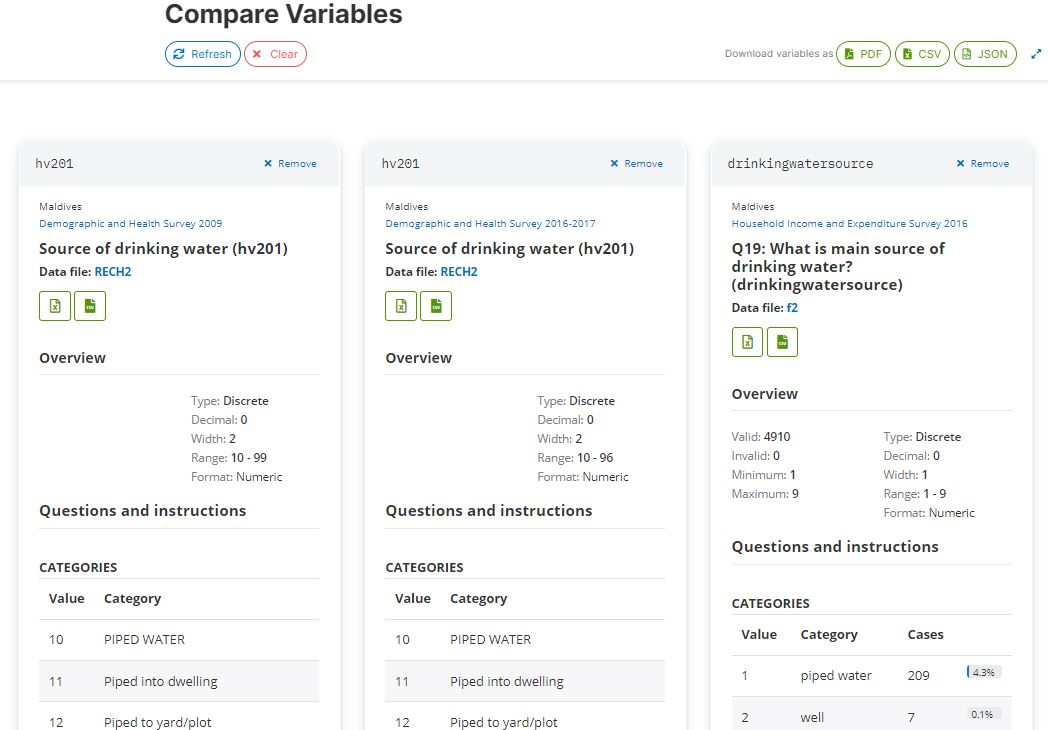
After selecting the variables of interest, users should be able to display their metadata in a format that facilitates comparison. The availability of detailed metadata is crucial to ensure the quality and usefulness of these comparisons. For example, when working with a survey dataset, capturing information on the variable universe, categories, questions, interviewer instructions, and summary statistics would be ideal. This comprehensive metadata will enable users to make informed decisions about which variables to use and how to analyze them.
2.1.3.6 Mosaic view for images
If the catalog contains entries of type “image”, a mosaic view should be provided in addition to the listing view. The availability of a mosaic view in an image catalog offers users a highly convenient and visually intuitive way to explore and navigate through a large collection of images. A mosaic view typically presents a grid or tiled layout of images, allowing users to see multiple thumbnails simultaneously on a single screen.
Here are several conveniences for users provided by a mosaic view in an image catalog:
- Efficient visual scanning: A mosaic view enables users to efficiently scan and preview a large number of images at once. This is particularly valuable when users are seeking specific images or trying to get a quick overview of the content available in the catalog.
- Rapid identification: Users can quickly identify images of interest based on their visual content without the need to open individual files. The mosaic layout provides a holistic view, aiding in the rapid identification of relevant images.
- Contextual understanding: Seeing images side by side in a mosaic view allows users to grasp contextual relationships and patterns that may not be apparent when viewing images individually. This is particularly beneficial when exploring thematic or chronological relationships among images.
- Streamlined selection process: Users can efficiently select multiple images for further actions, such as downloading, sharing, or organizing. This streamlines the selection process, enhancing user productivity and reducing the time required to interact with the catalog.
- Enhanced user experience: The visual appeal of a mosaic view enhances the overall user experience. It provides an engaging and interactive way for users to interact with the image catalog, making the exploration of images more enjoyable and user-friendly.
The images should also be organized into albums.
2.1.3.7 Data preview
The inclusion of a data preview feature in a data catalog is convenient for users as it allows them to get a quick glimpse of the dataset’s content without having to download or open the entire file. This feature is particularly beneficial for assessing data relevance, structure, and quality before committing to a full download or exploration.
For tabular data, such as indicators or microdata, the convenience is further amplified by various options to display the data in user-friendly data grids. These grids present the tabular data in a structured and readable format, making it easy for users to interpret and analyze the information. Additionally, the preview feature often accommodates customization options, allowing users to choose specific columns or rows for display, focusing on the most relevant aspects of the data.
In the case of large datasets, a preview feature typically offers a sample of the data rather than the entire dataset. This is practical for several reasons. First, it provides users with a representative subset of the data, offering insights into its characteristics without overwhelming them with excessive information. Second, displaying a sample helps manage resource constraints associated with loading and rendering large datasets, ensuring a smooth and responsive user experience.
The implementation of such a feature requires that the data be available via API.
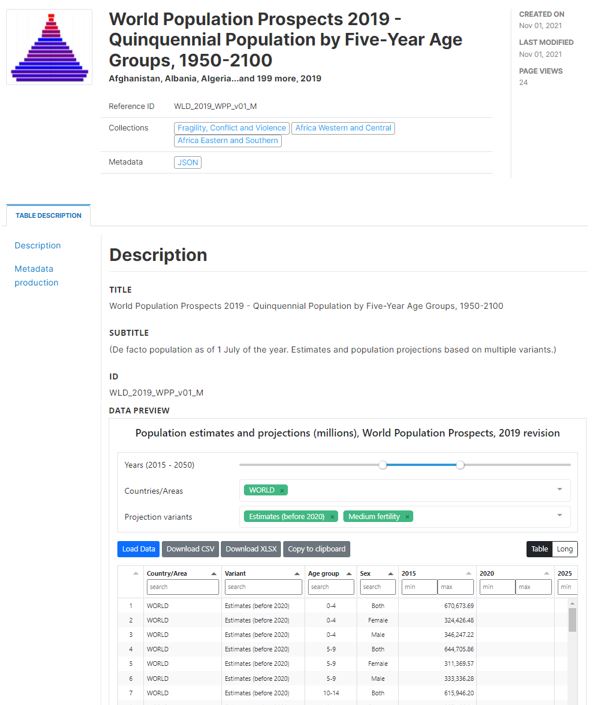
For data of type “document”, the “data preview” would consist of a document viewer that would allow the user to view the document within the application (even when the document is not stored in the catalog itself but in an external website). When implementing such a feature, check that the terms of use of the origination source allows that.

image
For data of type “video”, an option to play the video in the catalog itself should be provided. Typically, this will require publishing the video in an on-line service like Youtube, and embedding it into the catalog page.
2.1.3.8 Visualizations
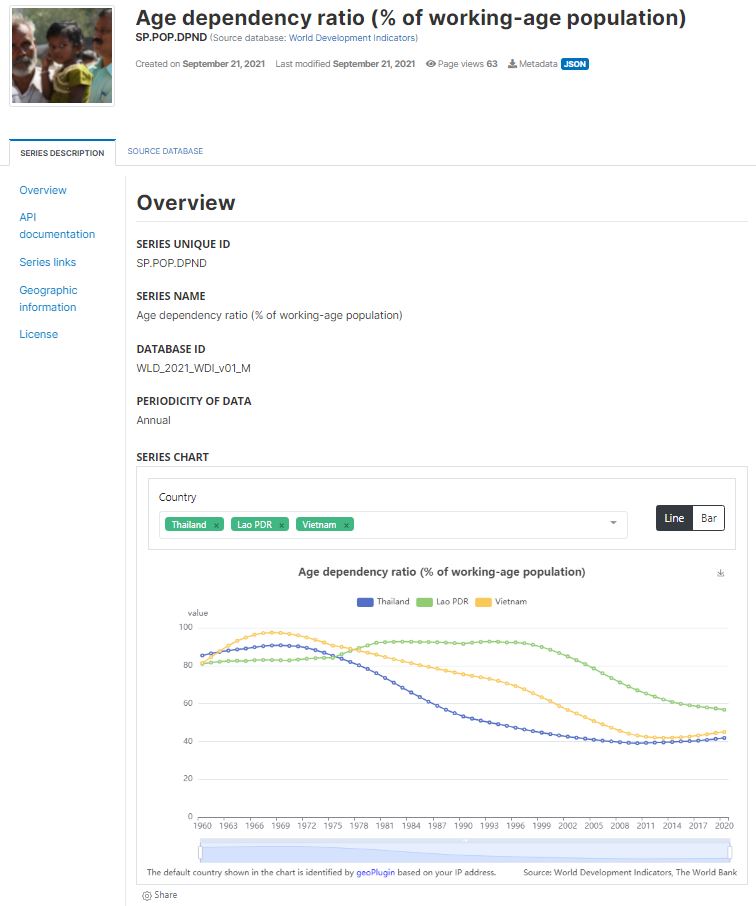
Integrating visualizations into a data catalog significantly enhances its utility by providing users with an immediate, insightful understanding of the data. Visualizations serve as powerful tools for efficient data comprehension and analysis. Tailoring the visualization type to the nature of the data is crucial; for instance, time series data can be effectively communicated through line charts, while geographically tagged images find clarity on a map. For more intricate datasets, diverse chart types can be employed. Embedding dynamic charts into catalog pages requires data accessibility through APIs. An effective data catalog should offer versatility in the types of charts and maps that can be integrated into metadata pages. The system should support the development of widgets using various tools, such as open-source JavaScript libraries. These widgets, combined with API-accessible data, enable the presentation of custom visualizations in a flexible manner. Establishing a repository of visualizations and widgets simplifies their implementation, ensuring users can effortlessly leverage these tools for enhanced data exploration and interpretation.
Example: Line chart for a time series
2.1.3.9 Links and related resources
The provision of information on links between different entries within a data catalog is useful to users who may not have a precise understanding of what they are seeking and rely on exploration to discover pertinent resources. These relationships can be systematically documented in the metadata. Examples include designating datasets as part of a series or indicating new versions of previous datasets.
When explicit relationships are not pre-defined, machine learning tools, such as topic models and word embedding models, can dynamically establish the topical or semantic closeness between diverse resources. This lays the foundation for implementing recommender systems within data catalogs, automatically identifying and showcasing related documents and data for a given resource. By leveraging these techniques, users benefit from an intuitive exploration experience, wherein they not only access the desired resource but also discover interconnected datasets and documents that augment their understanding and analysis.
2.1.4 Sorting
In a well-structured data catalog, the inclusion of a robust sorting feature is important for user-friendly navigation. Users often need the flexibility to arrange entries based on key features, such as the entry title, year, date of addition or last modification, and geographic area. A sorting mechanism enables users to tailor their exploration based on specific criteria, streamlining the process of finding relevant datasets. To ensure the effectiveness of sorting, employing controlled vocabularies where relevant becomes essential, particularly for metadata fields like geographic coverage. Consistent naming conventions, such as uniform country names throughout the catalog, prevent inconsistencies that might arise from variations in naming conventions. This not only enhances the catalog’s overall usability but also ensures that users can confidently and seamlessly leverage the sorting feature to pinpoint the datasets most relevant to their needs.
2.1.5 Other features for users
2.1.5.1 Data and metadata API
In meeting the demands of contemporary data management, a forward-thinking data catalog must not only house datasets but also provide users with streamlined access to both data and metadata, facilitated through an intuitive application programming interface (API). By integrating an API, users gain the efficiency of automated access to datasets or subsets, fostering a dynamic and agile data exploration experience.
Comprehensive documentation of API access within data catalogs is crucial for effective utilization. A standardized and detailed API description serves as a guide, elucidating functionalities, parameters, and responses for users and developers. For each dataset accessible via API, providing illustrative examples of API calls, coupled with a user-friendly API query builder, enhances user understanding and expedites integration.
Additionally, clear documentation on pagination mechanisms, the necessity (or lack thereof) for obtaining an API key, and delineation of good and bad practices adds critical context. Highlighting limitations imposed on API usage is equally vital, setting expectations regarding rate limits, data extraction constraints, and any other restrictions. This comprehensive documentation approach ensures transparency, accessibility, and empowers users to navigate the API seamlessly while understanding the nuances of its usage within the data catalog.
Ensuring that both data and metadata are accessible through the API is fundamental to maximizing the utility of a modern data catalog. Transparency about the availability of datasets accessible via the API, clearly communicated within the dataset card and accompanied by user-friendly filtering options, enhances the user experience by allowing users to identify and prioritize datasets that align with their preferred access method.
By providing access to the full data and metadata via API, the data catalog provides “data as a service” which allows users to build their own applications, such as specialized dashboards. Such a system is particularly efficient and cost-effective, as it allows multiple front-end applications to be served by a common back-end data system, thereby avoiding the need for duplication of data curation and storage.
To further enhance user engagement and understanding, comprehensive documentation and guidelines detailing the nuances of using the data and metadata API are indispensable. This includes not only a clear delineation of functionalities but also illustrative examples that empower users to navigate and leverage the API effectively. The incorporation of an API query builder within the user interface adds an extra layer of accessibility, simplifying the process of constructing and executing API queries.
While implementing limitations is a prudent practice, transparency in communicating these constraints is crucial. Whether it involves the need for an API key, permission systems, monitoring protocols, or security measures, users should be informed of these aspects upfront. A
2.1.5.2 Bulk download option
A data catalog should provide users with the option for bulk downloading datasets of indicators, even amidst alternative access options such as API access, data visualizations, or query interfaces. This option caters to a diverse user base, acknowledging that some users may prefer a straightforward, one-click method to obtain the complete dataset. Bulk downloading ensures accessibility for individuals who might not possess the technical expertise or inclination to engage with APIs or explore intricate query interfaces. It simplifies the user experience, providing a convenient means to acquire the entire dataset effortlessly.
Furthermore, the provision of datasets in a popular and at least one non-proprietary format ensures broad compatibility and ease of use for a wide range of users. Whether for offline analysis or integration into various tools, offering datasets in standard formats enhances versatility and eliminates potential barriers associated with proprietary formats.
Embedding metadata within the bulk download package is equally crucial, providing users with comprehensive context and documentation about the dataset. This ensures that users, even those opting for bulk downloads, have access to essential information about the dataset’s origin, methodology, and relevant details, fostering transparency and informed data utilization.
2.1.5.3 Alerts
The inclusion of an automated alert feature represents a significant convenience for users, streamlining the process of staying informed about newly added (or updated) datasets that align with their specific interests and criteria. This feature transforms the data catalog into a proactive tool, ensuring that users are promptly notified whenever datasets of relevance are introduced. This proactive approach enhances user efficiency by eliminating the need for constant manual monitoring and search efforts.
To empower users in defining their criteria for relevance, the system must offer a user-friendly interface for creating customized queries and setting them as alerts. Users can set up filters based on various parameters such as geographic coverage, specific topics, or other relevant attributes. This intuitive query creation process enables users to precisely articulate their preferences, ensuring that the alerts are tailored to their unique requirements.
The alert notifications are delivered via email to provide a timely and accessible update.
Recognizing the dynamic nature of user preferences, the system includes an option for users to easily cancel or modify their alert settings at any time, offering flexibility and control over the information they receive.
2.1.5.4 Time series query user interface
For catalogs that contain time series data, developing a user interface that simplifies the extraction and dissemination of indicators provides an additional convenient mode of access to users. A well-designed interface should empower users to effortlessly select one or multiple indicators, choose specific geographic areas, and define desired time periods. This user-friendly approach enhances the efficiency of data retrieval, catering to diverse user needs and research requirements.
The interface should seamlessly translate these user selections into a query, providing a clear representation of the chosen parameters. Additionally, to enhance versatility, the system should offer options to download the queried data in various formats, such as CSV or other commonly used file types. This facilitates easy integration of the obtained data into different analytical tools and platforms.
To further optimize the user experience and facilitate collaboration, the system should automatically convert the user-generated query into an API query. This functionality not only streamlines the process for users but also allows them to save and share their queries effortlessly. The ability to save and share API queries enhances collaboration, enabling users to exchange valuable insights and streamline data-driven decision-making processes.
2.1.5.5 Online data access forms
Facilitating access to non-public datasets through a streamlined and secure process is paramount for the success of an online data catalog. Providing users with a convenient means to request access to restricted datasets not only ensures compliance with privacy and security measures but also encourages a collaborative and transparent data-sharing environment. The inclusion of a registration mechanism within the catalog enables users to create accounts, establishing a secure and authenticated identity.
To request access, users can utilize an online form integrated into the catalog, simplifying the submission process. This form allows requesters to articulate their need for specific datasets and provide relevant context for their usage. The entire access request workflow, from submission to approval, is managed within the dissemination platform. This centralized control ensures a consistent and efficient process.
Communication between the requester and the approver is a crucial aspect of this access management system. The platform should offer dedicated channels for dialogue, notifications, and status updates to keep all stakeholders informed throughout the request and approval stages. Additionally, a comprehensive logging system records all actions taken during the access request process. This traceability and auditability feature not only enhances accountability but also facilitates compliance with regulatory requirements and internal data governance policies.
By integrating these functionalities, an online data catalog not only safeguards the confidentiality of non-public datasets but also fosters a transparent and accountable data-sharing ecosystem. Users benefit from a straightforward process, while administrators gain the tools needed to effectively manage and monitor access requests, ultimately promoting responsible and secure data dissemination.
2.1.5.6 Permanent identifiers and DOIs
Establishing a globally unique and permanent identifier for each dataset within a data catalog is pivotal for efficient data management and organization. This unique identifier not only serves technical purposes but also plays a crucial role in various aspects, including facilitating dataset citation, tracking data usage, and ensuring long-term accessibility.
A globally unique identifier is essential to distinguish datasets unambiguously, preventing potential confusion or mismanagement, especially in large and diverse data catalogs. Beyond technical requirements, these identifiers serve as a cornerstone for systematic data citation, a practice increasingly recognized as vital for acknowledging data contributors and enhancing reproducibility in research.
To achieve the highest level of effectiveness, it is recommended to assign a Digital Object Identifier (DOI) as a globally unique identifier for datasets. DOIs provide a permanent and persistent link to the dataset, even if the dataset undergoes changes or is relocated. Generating DOIs can be achieved through registration with a DOI registration agency, ensuring a standardized and widely accepted method for unique identification.
In addition to a catalog-specific identifier, the DOI enhances the discoverability and accessibility of datasets, making them citable entities in scholarly publications. Researchers and data users can easily reference the dataset in their work by including the DOI in citations. This practice not only gives proper credit to data contributors but also contributes to the traceability of data usage in research publications.
To reinforce the importance of proper dataset citation and to streamline tracking, it is advisable to include a citation requirement as part of the conditions imposed on users accessing the data. By mandating the inclusion of the DOI or other unique identifier in publications, data providers ensure a transparent and accountable system for tracking the use of datasets over time. This holistic approach to dataset identification and citation not only supports efficient data management but also aligns with best practices in scholarly research and data stewardship.
2.1.5.7 Archiving
Preserving old versions of datasets within a data repository and catalog is indispensable for ensuring the reproducibility of analyses and supporting the diverse needs of users. When datasets are removed or replaced without retaining previous versions, the ability to replicate analyses and validate results may be compromised, posing a challenge for researchers and analysts who rely on historical data configurations.
Maintaining accessibility to old versions is crucial unless there are specific reasons for restricting access. These older iterations provide valuable insights into the evolution of datasets over time and are essential for those users whose analyses depend on specific historical data points. However, to mitigate confusion and guide users towards the most current information, it is advisable not to index and prominently display old versions in the main catalog.
A pragmatic approach involves relocating replaced datasets to an archive section within the catalog, making them accessible but not prominently featured or indexed. This ensures that users seeking the latest information encounter the most recent dataset versions by default, minimizing the risk of unintentional use of outdated data. It is worth noting that while Digital Object Identifiers (DOIs) necessitate a permanent web page, maintaining an archive section within the catalog allows for the preservation of historical dataset versions while adhering to best practices in data management and version control. This approach not only safeguards the reproducibility of analyses but also accommodates the diverse needs of users engaged in longitudinal studies or analyses reliant on specific historical data snapshots.
2.1.5.8 Catalog of citations
Expanding the scope of a data catalog to include a comprehensive catalog of publications, both academic and otherwise, that cite the datasets listed within, is a strategic move that significantly enriches the utility of the catalog for its users. Beyond being a repository solely for data, this enhanced catalog becomes a dynamic hub that captures the entire lifecycle of research projects, providing a holistic view of the data’s impact and utilization.
Access to a catalog of citations serves as a valuable resource for users interested in a particular dataset. It offers a window into the diverse ways the dataset has been utilized in academic and other contexts, shedding light on the variety of research questions it has helped address. Understanding the previous uses and users of the data not only aids potential acquirers in assessing the dataset’s relevance but also provides valuable context for its potential applications.
In an ideal data catalog, users should be empowered to seamlessly navigate between different components of the research process. This includes the ability to search for data and access related scripts and citations, search for analytical outputs and find associated data and scripts, and search for scripts to locate the relevant data and analytical outputs. This interconnected ecosystem ensures that users can trace the complete trajectory of a dataset, from its raw form to the analyses conducted, and finally, to the publications that have cited its findings.
Maintaining a catalog of citations not only fosters transparency and accountability in the use of data but also encourages a collaborative and interconnected research community. Researchers can learn from each other’s methodologies and findings, fostering a culture of knowledge-sharing.
Utilizing artificial intelligence (AI) in the process of cataloging citations of datasets within academic and other publications represents a cutting-edge advancement in automated metadata augmentation. Modern technologies enable AI algorithms to systematically scan and analyze vast amounts of textual data to detect instances where datasets are cited, providing a dynamic and efficient means of tracking how these datasets have been utilized. By leveraging machine learning capabilities, AI can discern patterns, relationships, and contextual nuances in the language used within publications, contributing to the creation of a comprehensive catalog of citations. This automation not only accelerates the cataloging process but also enhances the accuracy and scalability of tracking dataset citations, empowering users with a wealth of information on the diverse applications and impacts of the datasets housed within the catalog.

image
2.1.5.9 Reproducible and replicable scripts
Maintaining a catalog of reproducible data processing and analysis scripts as part of a data catalog helps foster transparency, collaboration, and the advancement of research endeavors. Such a catalog serves as a valuable repository for researchers, enabling them to validate and build upon the work of their peers. The availability of reproducible scripts promotes transparency in research practices, allowing fellow researchers to scrutinize methodologies and results. For junior analysts, this catalog provides a trove of valuable training materials, offering real-world examples to enhance their understanding of data processing and analysis techniques. More advanced researchers benefit by gaining access to the foundational work of their peers, providing a solid starting point for further exploration and innovation. In essence, a catalog of reproducible scripts is a cornerstone for cultivating a culture of openness and collaboration within the research community, contributing to the overall quality and rigor of scientific inquiry.

image
2.1.5.10 Users’ feedback
Facilitating user feedback within a data catalog allows the continuous improvement of both the cataloguing application itself and the content it houses. Establishing an accessible avenue for users to provide feedback, whether through a “Contact” email or more structured satisfaction survey forms, creates a valuable two-way communication channel. This direct line of communication empowers users to express their experiences, concerns, or suggestions, ensuring that the catalog aligns with their evolving needs.
However, it’s crucial to implement safeguards and define limits for the feedback system. While open feedback systems, akin to narrative reviews on e-commerce platforms, may be suitable for certain contexts, they pose unique challenges within the realm of data platforms. Not all users provide constructive and qualified feedback, and the absence of moderation could result in unreliable information. Negative feedback, if not managed carefully, might discourage data producers from contributing to the catalog, potentially hindering the platform’s growth.
For public data platforms, introducing measures such as attributed comments and an authentication system can enhance the reliability of feedback by ensuring accountability. However, even with these safeguards, constant moderation is necessary, which can be resource-intensive and may lead to controversial outcomes. Therefore, internal data platforms within an organization, where comments can be attributed and authenticated, may find open feedback systems more suitable, fostering a culture of accountability and improvement without risking the potential disincentives associated with unmoderated negative feedback in public data platforms.
2.1.5.11 Support
Ensuring robust support mechanisms within an online data catalog contributes to enhancing user experience and fostering a collaborative data community. One effective way to provide assistance is through a well-structured Frequently Asked Questions (FAQ) page. This resource can address common queries, guide users through the catalog’s features, and offer troubleshooting tips. A comprehensive FAQ page serves as an initial point of reference, enabling users to find solutions to their queries independently.
Additionally, offering a readily available contact email address is essential for addressing unique or complex user concerns that may not be covered in the FAQ. While administrators may have limitations in providing extensive one-on-one support, acknowledging user queries and directing them to relevant resources or documentation is crucial. The goal is to ensure that every user request, even if beyond the scope of direct assistance, receives a response that guides them toward helpful solutions or points of contact.
By combining a user-friendly FAQ page with responsive communication channels, the data catalog demonstrates a commitment to user support and community engagement. This approach acknowledges the diverse needs of users and provides them with the necessary tools to navigate the platform successfully, even when faced with unique challenges.
2.1.5.12 Conversational interaction with datasets
Generative AI, particularly in the form of Large Language Models (LLMs), has emerged as a promising avenue for revolutionizing user interactions with datasets by enabling conversational interfaces. This innovative approach allows users to engage with data in a more natural and intuitive manner, resembling a conversation. While LLMs have excelled in interacting with text data, their application to structured datasets, such as databases and statistical tables, is still in the early stages, though progress is being made.
Currently, the capacity of LLMs to understand and interact with structured data is somewhat limited, and challenges like accurate interpretation and contextual understanding persist. Despite these challenges, the field is evolving rapidly, with ongoing research aimed at enhancing the capabilities of generative AI to handle diverse data formats. Organizations with advanced technical capabilities are beginning to experiment with implementing conversational interfaces for datasets, but it’s essential to caution users about potential risks, including the phenomenon of hallucination, where the AI may generate inaccurate or unintended information.
As this approach remains exploratory, organizations should approach its implementation with careful consideration and provide clear warnings to users about the inherent limitations and risks. The fast-paced development in this field, however, suggests that these challenges are not insurmountable, and improvements are expected to occur rapidly. In the near future, generative AI may offer new and powerful ways to disseminate data, especially benefiting users who lack technical expertise in traditional data processing methods.
One promising aspect of using generative AI for dataset interfaces is the potential to address language barriers. Many LLMs possess multilingual capabilities, allowing users to interact with datasets in their preferred language. This not only enhances accessibility but also opens up opportunities for a more inclusive and global approach to data exploration. As advancements continue and researchers address the existing challenges, generative AI holds the potential to transform the landscape of data interaction, providing users with unprecedented access and understanding, ultimately democratizing data utilization for a broader audience.
2.1.5.13 AI-activated assistance to data analysis
A data catalog may also consider providing options for users to exploit Artificial Intelligence for data analysis. AI has demonstrated significant potential in supporting data analysis by assisting data users in writing scripts across various programming languages such as R, Python, or Stata. This capability, exemplified by applications like GitHub Copilot, streamlines the process of code creation, enhancing the productivity of data users, particularly those who may not be proficient programmers.
One notable advantage of AI-powered script generation is the acceleration of the data analysis workflow. By leveraging machine learning models, these applications can predict and suggest code snippets or even complete scripts based on contextual cues and user input. This not only reduces the time required for coding but also enables users with diverse skill sets to engage in data analysis without extensive programming expertise.
However, it is crucial to emphasize that while AI can significantly enhance efficiency, it does not replace the need for data analysts to possess a thorough understanding of the data they are working with and the limitations inherent in the datasets. The role of data analysts remains pivotal in formulating meaningful research questions, designing robust analyses, and interpreting results accurately. Additionally, the application of AI-generated scripts necessitates careful validation by data analysts to ensure the accuracy and reliability of the generated code.
GitHub Copilot, as an example, utilizes OpenAI’s Codex, a powerful language model, to assist developers in writing code snippets and completing entire functions. While this tool can be immensely valuable, especially for routine or repetitive coding tasks, it is essential to approach AI-generated scripts with a critical eye. Data analysts must remain vigilant about potential biases, inaccuracies, or oversights introduced by the AI, and they play a crucial role in validating and refining the code to align with the specific requirements of the analysis.
In conclusion, the integration of AI in supporting data analysis through script generation presents a valuable opportunity to boost productivity and inclusivity in data-driven tasks. However, this augmentation does not diminish the indispensable role of data analysts in understanding the intricacies of the data and validating the scripts. A synergistic collaboration between AI tools and human expertise ensures a more robust, accurate, and insightful data analysis process.
2.2 Features for data providers
Many data catalogs are not administered by the data producers themselves but by an entrusted repository who collcets data from multiple sources. Data producers who entrust a data repository for the preservation and dissemination of their data will have various legitimate expectations.
2.2.1 Safety
The importance of safety in an online data catalog extends beyond technical measures to encompass legal, ethical, and communicative aspects.
For data providers considering the publication of their datasets in an online data catalog, ensuring the safety and responsible use of their data is essential. Safety measures must be implemented to protect data against intentional or accidental misuse, which can pose significant risks to the reputation of the data provider. Establishing a robust framework for data protection not only safeguards sensitive information but also instills confidence in data contributors, fostering a trustworthy and collaborative data-sharing environment.
Data providers seek assurances that the regulations and terms of use governing the data catalog will be strictly adhered to. This includes compliance with data protection laws, intellectual property rights, and any other relevant legal and ethical standards. A transparent and enforceable set of terms ensures that the data will be utilized responsibly, addressing concerns related to privacy, security, and the overall integrity of the data.
The data catalog should implement stringent access controls, authentication mechanisms, and encryption protocols to prevent unauthorized access. Clear policies on data sharing, attribution, and usage restrictions further contribute to the safety of the data. Data providers often appreciate platforms that offer features like restricted access to sensitive datasets, ensuring that only authorized users can retrieve and utilize the information.
Additionally, communication and transparency are vital components of safety assurance. Clear and comprehensible documentation on how the data will be handled, who has access, and the purposes for which it can be used helps to build trust between data providers and the platform administrators. Regular updates on security measures and any changes to data handling policies further reinforce the commitment to data safety.
By prioritizing data safety, platforms can attract high-quality datasets, establish long-term partnerships with data providers, and contribute to the responsible and ethical use of shared information.
2.2.2 Visibility
For data providers contemplating the publication of their datasets in an online data catalog, maximizing the visibility of their data is paramount to unlocking its full potential value. Enhanced visibility ensures that the datasets reach a broader audience, increasing the likelihood of meaningful use, collaboration, and impactful contributions to research and analysis. Consequently, data providers expect the data catalog to implement various measures, including search engine optimization (SEO), to boost the discoverability of their datasets.
A well-optimized data catalog employs SEO strategies to improve the ranking of datasets in search engine results. This involves optimizing metadata, keywords, and descriptions to align with common search queries related to the dataset’s content. By doing so, the data becomes more accessible to researchers, analysts, and other potential users who may be searching for specific datasets or information.
Beyond SEO, effective data categorization and tagging within the catalog contribute to visibility. Clear and comprehensive metadata, including relevant keywords, helps potential users understand the dataset’s content and purpose quickly. Data providers appreciate catalogs that offer advanced search functionalities, allowing users to filter and refine their searches based on specific criteria, thus enhancing the precision of dataset discovery.
The visibility of datasets can also be amplified through strategic partnerships, cross-referencing, and integration with other relevant platforms and repositories. Collaboration with research communities, academic institutions, and industry organizations can further expand the reach of the datasets, creating valuable connections and increasing the likelihood of data reuse.
A combination of SEO strategies, robust metadata, advanced search capabilities, and strategic partnerships collectively ensures that datasets are not only discoverable but also effectively utilized by a diverse and engaged user base, ultimately maximizing the impact and value of the shared data.

image
2.2.3 Efficiency
For data providers contemplating the publication of their datasets in an online data catalog, an efficient data deposit system is instrumental in reducing the burden associated with the deposition process and supporting the catalog administrator. Many data providers might lack expertise in intricate aspects of data documentation, protection, and dissemination, making it imperative that the deposit process is streamlined and user-friendly. The ease of deposit significantly influences a data provider’s willingness to contribute, making a low burden deposition system essential for encouraging widespread data sharing.
An efficient data deposit system minimizes the effort required from data providers by simplifying the documentation process. The system should guide data contributors through the steps of providing comprehensive metadata, ensuring that essential information about the dataset is accurately captured. Automation features, where possible, can further expedite the deposition process, allowing data providers to focus on the content of their datasets rather than navigating complex submission procedures.
Moreover, to alleviate the burden on data providers, the catalog system should take on the responsibility of supporting users. A well-designed catalog should offer a user-friendly interface and provide comprehensive documentation, reducing the need for users to interact directly with data providers for basic inquiries. This not only eases the workload on data contributors but also fosters a more self-sufficient and efficient user experience.
Completeness of documentation (metadata) is critical for minimizing user interactions with data providers. A well-documented dataset, rich in metadata, enables users to understand the content, methodology, and potential applications without requiring extensive communication with the data provider. This completeness ensures that the catalog becomes a standalone resource, reducing the need for users to seek additional clarification from the data provider.
In summary, an efficient data deposit system is pivotal for data providers, promoting their willingness to contribute to an online data catalog. By streamlining the deposition process, automating where possible, and ensuring comprehensive documentation, the burden on data providers is reduced. Simultaneously, a well-designed catalog system supports users, minimizing the need for direct interactions with data providers and reinforcing the self-sufficiency of the platform. This symbiotic approach contributes to a seamless and collaborative data-sharing ecosystem. ### Information on usage
Monitoring of usage (downloads and citations) to assess demand; reports on this (automatically generated) API and downloads etc
2.2.4 Feedback from users
For data providers choosing to publish their datasets in an online data catalog, the importance of receiving feedback from users on various dimensions of data quality cannot be overstated. Feedback serves as a valuable mechanism for continuous improvement, offering insights that allow data producers to refine their data collection methods, enhance the accuracy of their datasets, and improve documentation. This iterative feedback loop not only contributes to the overall quality of the shared data but also fosters a collaborative and responsive relationship between data providers and users.
Feedback on the relevance of the data helps data providers understand the practical utility of their datasets within different research or analytical contexts. This insight enables them to prioritize certain aspects of their data collection efforts, ensuring that the datasets align more closely with the needs of the user community.
Accuracy feedback is crucial for data providers striving to maintain the highest standards in their datasets. Users may identify discrepancies, errors, or areas for improvement in the data, prompting data providers to rectify inaccuracies and enhance the overall precision of the information they share.
Documentation feedback is equally valuable as it sheds light on how well users can understand and utilize the metadata accompanying the datasets. Clear and comprehensive documentation is key to facilitating effective data use, and user feedback in this realm helps data providers refine their documentation practices for better user understanding.
Beyond these dimensions, feedback on other aspects of data quality can encompass issues such as completeness, timeliness, and consistency. The insights gained from user feedback empower data providers to make informed adjustments to their data collection methodologies, instruments, and documentation processes, ensuring that the datasets remain relevant, accurate, and valuable to the user community.
Ultimately, the feedback loop between data providers and users is a cornerstone of a dynamic and responsive data-sharing ecosystem. It fosters collaboration, supports continuous improvement, and ensures that the shared datasets not only meet but exceed the expectations of the user community, resulting in a more robust and impactful data catalog.
2.3 Features for catalog administrators
In addition to meeting the needs of data users and producers, a modern data catalog must offer features to make the role of catalog administrator efficient and cost-effective.
2.3.1 Data deposit
The administrators of a central data catalog bear a crucial responsibility in ensuring the efficiency and integrity of the data deposit system. A robust online data deposit system serves as the gateway for data producers and contributors to submit their datasets in a formal, well-organized manner. Its importance lies in its ability to provide a secure environment, incorporating a rigorous authentication system and other security measures to safeguard sensitive data.
User-friendliness is paramount, encouraging contributors to deposit data seamlessly, while compliance with metadata standards facilitates the submission of structured metadata that catalog administrators can easily process.
The data deposit system must provide an option for data depositors to flag any particular issue related to data privacy, confidentiality, or copyrights, and to inform the data repository of any other possible restrictions to the access and use of the data. The system should also provide an option to provide information on possible embargo.
Facilitating collaboration, the data deposit system should allow multiple contributors to contribute to a dataset submission, fostering collective data curation. To demonstrate compliance with rules and standards, the system must generate comprehensive documents, logs, and evidence. Incorporating embedded quality control mechanisms ensures the submitted data meets predefined standards, enhancing the overall reliability of the catalog.
Furthermore, a user-friendly interface should empower catalog administrators to orchestrate the processing pipeline, enabling tasks assignment to the data curation team. This feature enhances efficiency, coordination, and transparency in the data management workflow.
As a comprehensive tool, the data deposit system should evolve to accommodate evolving requirements and technologies, ensuring its long-term viability in supporting the catalog’s mission to provide organized, secure, and high-quality datasets for users.
2.3.2 Privacy protection
For administrators of a central data repository or library, implementing robust tools for data protection is paramount in safeguarding the privacy and integrity of the stored datasets. It is crucial to have sophisticated mechanisms to detect instances where personal information may be inadvertently included in a dataset. While organizations or individuals depositing data are typically asked to provide information on whether their datasets contain sensitive information requiring data privacy measures, administrators cannot solely rely on this self-disclosure.
To bolster data protection, administrators must employ comprehensive tools for statistical disclosure control. These tools play a vital role in anonymizing or modifying datasets to prevent the disclosure of individual identities or sensitive information. This includes techniques such as data masking, aggregation, or perturbation to strike a balance between data utility and privacy.
While depositors’ information on potential privacy concerns is valuable, administrators must conduct their own additional checks. This involves utilizing advanced algorithms and pattern recognition techniques to identify and address any potential privacy risks within the datasets. These independent assessments are crucial in ensuring compliance with data protection rules and principles, mitigating the risk of unintentional data leaks or privacy breaches.
Moreover, administrators should establish a proactive approach by continuously updating their tools and practices to align with evolving data protection standards and regulations. Regular training for administrators on the latest privacy-preserving techniques and emerging threats is essential to maintaining a vigilant and responsive data protection infrastructure. By integrating a multi-faceted approach that combines depositor disclosures with rigorous internal checks, administrators can uphold the highest standards of data protection within a central repository, fostering trust among data depositors and users alike.
2.3.3 Free software
The use of open-source software confers numerous advantages upon administrators of a data catalog. One key benefit lies in the flexibility it offers, enabling customization and adaptation to specific organizational needs and workflows. Open-source solutions provide transparency into the source code, allowing administrators to delve into the inner workings of the software, understand its functionality, and make tailored modifications to align with evolving requirements.
Cost-effectiveness is another compelling advantage, as open-source software typically eliminates licensing fees associated with proprietary alternatives. This financial flexibility allows organizations to allocate resources strategically, directing funds towards additional enhancements, user training, or expanding the catalog’s capabilities.
The collaborative nature of open-source communities is a valuable asset for administrators. They can leverage a collective pool of knowledge, benefit from ongoing development efforts, and contribute to the software’s improvement. This collaborative ethos fosters innovation, ensures timely updates, and provides a community-driven support network.
Additionally, open-source solutions often have a strong emphasis on interoperability, allowing seamless integration with other tools and systems. This interoperability enhances the catalog’s efficiency by facilitating the exchange of data and workflows with complementary applications, further enriching the overall data management ecosystem.
2.3.4 Security
The importance of deploying a secure system for administrators of an online data catalog cannot be overstated. A reliable and robust security infrastructure is essential to safeguard sensitive and confidential information within the catalog. Security requirements for an online data dissemination system should encompass various aspects to ensure comprehensive protection. This includes robust access controls to manage user permissions effectively, encryption mechanisms to secure data both in transit and at rest, and secure authentication processes to verify the identity of users.
Furthermore, administrators should prioritize audit trails and logging functionalities to monitor user activities and detect any anomalous behavior. Regular security updates and patches are imperative to address vulnerabilities promptly and mitigate potential risks. A well-defined incident response plan should also be in place to handle security breaches efficiently and minimize their impact.
Importantly, any system used for the operation of an online data catalog should undergo accreditation by information security specialists. This ensures that the system adheres to industry best practices and complies with relevant security standards and regulations. Security specialists can assess the system’s vulnerability to potential threats, verify the implementation of security controls, and validate its overall resilience against cyber threats.
Regularly applying upgrades and patches is crucial, as it ensures that the system remains fortified against emerging threats by addressing vulnerabilities and incorporating the latest security enhancements.
By prioritizing a system with these security measures in place and seeking accreditation from security experts, administrators can instill trust in users and stakeholders, assuring them that the online data catalog is fortified against unauthorized access, data breaches, and other security risks. This proactive approach not only protects sensitive information but also upholds the integrity and reliability of the data catalog as a trusted resource for data dissemination.
2.3.5 IT affordability
A system with manageable and affordable IT requirements must be chosen to operate the data catalog and dissemination system. The potential challenges and costs associated with maintaining extensive IT infrastructure must be evaluated. A system with moderate IT demands not only reduces operational expenses but also ensures greater accessibility, making it feasible for a broader range of organizations to implement and maintain an online data catalog. Particularly in environments where financial resources may be constrained, a system with minimal IT requirements becomes a pragmatic choice, allowing administrators to allocate resources judiciously.
Implementing advanced features such as recommender systems and other AI-based functionalities undoubtedly adds value to a data catalog, enhancing user experience and data exploration capabilities. However, it is crucial for administrators to strike a balance, as these advanced features often come with increased IT demands. The challenge lies in selecting a system that integrates these functionalities seamlessly without imposing excessive strain on the IT infrastructure. By carefully evaluating the trade-offs between advanced features and infrastructure requirements, administrators can ensure that the online data catalog remains efficient, cost-effective, and accessible to a diverse user base.
2.3.6 Interoperability
Given that data catalogs frequently operate in collaboration with data curation and dissemination systems maintained by other organizations or other units within the same organization, it is crucial to facilitate the exchange of content in a mostly automated manner, fostering machine-to-machine interactions when permissible and relevant. This collaborative approach ensures a seamless flow of information across diverse systems, promoting efficient data management and utilization within interconnected data ecosystems.
System interoperability offers a host of advantages that contribute to enhanced efficiency and expanded data accessibility. When online data catalogs rely on metadata standards and are API-based, they foster seamless interoperability, allowing for more effective collaboration and integration with other catalogs and applications. This interoperability not only ensures compatibility between systems but also enables the exchange of data and metadata in a standardized and cohesive manner.
A key advantage of system interoperability is the facilitation of data visibility across multiple catalogs and hubs. By adhering to common metadata standards and utilizing API-based communication, online data catalogs can publish metadata in a consistent format, increasing data discoverability and maximizing the service provided to users. This interoperability promotes a connected data ecosystem where administrators can leverage shared resources, avoid data silos, and streamline data dissemination processes.
To achieve effective interoperability, automation plays a pivotal role. Proper synchronization between catalogs, with one catalog designated as the “owner” of a dataset, requires automated processes that are enabled by interoperable systems. This ensures that updates, additions, or changes to datasets are reflected accurately across interconnected catalogs, maintaining data consistency and reliability.
Furthermore, compliance with common formats, metadata standards, and schemas becomes imperative in establishing a shared language for data exchange. When online data catalogs embrace interoperability through standardized practices, administrators can not only benefit from streamlined data management but also provide users with a cohesive and interconnected experience, ultimately enhancing the utility and reach of the data catalog within the broader data ecosystem.
2.3.7 Flexibility on access policies
An online data cataloging system must be able to accommodate a diverse array of access policies and terms of use to foster a collaborative and inclusive data-sharing environment. While the ideal scenario involves attaching a standard license to each dataset, the reality is that datasets may come with varied access requirements and terms. A robust cataloging system should recognize and adapt to this diversity, allowing administrators to customize access policies and terms of use for each dataset individually.
The ability to handle a range of access policies is crucial for accommodating the preferences and restrictions set by data depositors. Some datasets may be open for public use, while others might have more stringent access controls based on factors like user roles, affiliations, or project requirements. A lack of flexibility in the cataloging system may deter potential data depositors who are hesitant to entrust their datasets to a platform that cannot align with their specific access and usage conditions.
In instances where datasets cannot be standardized with a predefined license, the cataloging system’s flexibility becomes even more critical. Data depositors may have unique legal or ethical considerations that necessitate bespoke terms of use, and a rigid system that does not allow for such nuances might dissuade them from contributing valuable datasets to the catalog.
2.3.8 API based system for automation and efficiency
An API-based system offers a plethora of advantages to administrators of online data catalogs, that significantly enhance efficiency and cost-effectiveness. The use of APIs allows for seamless integration with external systems, enabling administrators to automate various tasks related to the content of the catalog. One key advantage lies in automating data acquisition processes, facilitating the streamlined ingestion of new datasets into the catalog. This not only expedites the content update process but also ensures that the catalog remains current and reflective of the latest available data.
Moreover, an API-based system empowers administrators to automate metadata enhancement, leveraging external sources or algorithms to enrich dataset descriptions and attributes. This automation not only saves time but also enhances the comprehensiveness and accuracy of metadata, contributing to an enriched user experience.
Reporting on usage metrics is another area where API integration proves invaluable. By tapping into usage analytics tools or integrating reporting functionalities through APIs, administrators can effortlessly gather insights into how users interact with the catalog. This data-driven approach enables informed decision-making, helping administrators optimize the catalog’s content and features based on user behavior.
The overall efficiency gains from an API-based system extend to cost-effectiveness. Automation reduces the manual effort required for routine tasks, freeing up resources that can be redirected towards strategic initiatives or improvements in other areas of the catalog. Additionally, the adaptability of an API-based system ensures that the online data catalog can easily evolve and integrate with emerging technologies, staying at the forefront of data management practices.
2.3.9 Featuring tools
A data dissemination system should incorporate a feature allowing the catalog administrator to highlight and “feature” datasets deemed crucial for the mission of the organization managing the catalog. This option enables administrators to draw attention to specific datasets of high importance, aligning with the organization’s objectives. By promoting these key datasets, administrators can enhance their visibility, ensuring that users are more likely to discover and engage with the critical information that aligns with the organization’s mission. This highlighting feature not only serves as a strategic tool for information promotion but also adds a layer of curation, guiding users towards datasets that hold particular significance for achieving the organization’s goals.
2.3.10 Usage monitoring and analytics
Utilizing and appropriately configuring web usage analytics tools, such as Google Scholar, is integral for administrators of data catalogs to gauge and understand the demand for the data assets within the catalog. These tools offer valuable insights into user behavior, allowing administrators to quantify and qualify the level of interest in specific datasets. By leveraging such analytics, administrators can provide meaningful reports to both organizations and individuals who contribute data to the catalog. This information is crucial for demonstrating the impact and value of the data catalog, reinforcing its role as a vital resource for the organization.
One of the primary benefits of web analytics tools is the ability to track user interactions with the catalog. This includes details such as which datasets are frequently accessed, popular search queries, and user navigation patterns. Armed with this information, administrators can make informed decisions about optimizing the catalog’s structure, improving metadata, and enhancing search functionalities. For data contributors, these insights become powerful indicators of the relevance and impact of their contributions, fostering a sense of value and encouraging ongoing participation.
Furthermore, web analytics help administrators identify areas of the catalog that may need attention. If certain datasets receive limited attention, administrators can investigate potential reasons, such as unclear metadata or lack of discoverability, and take corrective measures. This proactive approach contributes to an overall improvement in the visibility and usability of the catalog, ensuring that it remains a dynamic and responsive platform for data users and producers alike.
The information obtained from web analytics tools plays a crucial role in tailoring the data catalog’s services to the needs of both data consumers and producers. By understanding user behavior, administrators can implement targeted enhancements, such as personalized recommendations, improved navigation pathways, or even curated collections based on popular topics. This not only enhances the user experience but also encourages continued engagement with the catalog, ultimately maximizing the utility of the data assets it houses.
2.3.11 Multilingual capability
A data cataloging and dissemination system should have multilingual capability. Developing the application with internationalization in mind, where it can seamlessly adapt to various languages, is a strategic move that caters to a diverse user base. Providing the capability to produce versions of the application in different languages ensures inclusivity and accessibility.
Moreover, deploying a multilingual system with the option to switch between languages is a user-centric feature that accommodates a broader audience. When catalog administrators have the flexibility to offer multiple language options, it enhances the user experience, making the system more user-friendly and accommodating for individuals who may not be proficient in the default language. This adaptability is particularly relevant in multinational organizations or collaborative research efforts where stakeholders may come from different linguistic backgrounds.
2.3.12 Search Engine Optimization (SEO)
Implementing Search Engine Optimization (SEO) is crucial for maximizing the visibility and accessibility of valuable data assets within an organization. A data catalog serves as a centralized repository that indexes and organizes various datasets, making it an essential tool for data management and discovery. Without effective SEO strategies integrated into the data catalog system, the wealth of information contained within might remain underutilized or even undiscovered by users.
In the context of online data catalogs, SEO involves optimizing the catalog’s structure, metadata, and content to ensure that search engines can easily index and rank the information. This optimization not only enhances the discoverability of specific datasets but also contributes to the overall efficiency of data governance within an organization. As more businesses rely on data-driven decision-making processes, the ability to quickly and accurately locate relevant datasets becomes paramount.
Data catalog administrators play a pivotal role in implementing SEO features within the cataloging system. They need to focus on key aspects such as metadata enrichment, clear taxonomy, and user-friendly interfaces. Metadata, which includes descriptions, tags, and other contextual information about datasets, should be meticulously crafted with relevant keywords to align with common search queries. A well-defined taxonomy ensures that data is organized logically, making it easier for users and search engines to navigate through the catalog.
Regularly updating and maintaining the catalog’s content and ensuring that it aligns with current industry standards and practices are also vital for sustaining SEO effectiveness. Catalog administrators need to stay informed about emerging trends in data management and adjust the catalog accordingly to maintain its relevance and visibility.
2.3.13 Widgets and plugins
A system designed for online data dissemination must embody modularity and flexibility to cater to diverse user needs and evolving functionalities. The ability to leverage plugins and widgets to augment the core application with custom features is a pivotal aspect of ensuring adaptability and customization. This modular design allows administrators of data catalogs to integrate and embed specialized tools seamlessly, enhancing the user experience and expanding the range of functionalities available within the platform.
For instance, the incorporation of plugins and widgets enables the seamless integration of customized visualization tools directly into a data catalog. Administrators can tailor the platform to meet specific requirements, offering users access to advanced visualization capabilities that align with their analytical needs. This not only enriches the data exploration experience but also empowers users to derive deeper insights from the presented information.
The advantages of a modular and extensible system extend beyond visualization tools, providing the framework to incorporate various functionalities and features tailored to specific use cases. This flexibility ensures that the online data dissemination system remains dynamic and responsive to the evolving demands of data administrators and end-users alike.
2.3.14 Interaction with developers
For administrators of an online data catalog, establishing a collaborative relationship with the designers and developers of the cataloging system is highly beneficial. This collaboration allows administrators to actively participate in the evolution and enhancement of the cataloging system, ensuring it remains responsive to evolving user needs and industry best practices. Regular communication between administrators and the design and development teams enables the implementation of user feedback, addressing usability issues, and introducing new features or optimizations. This iterative process ensures that the data catalog remains a dynamic and efficient tool, fostering a more seamless experience for both data contributors and users. The synergy between administrators and the technical teams contributes to the ongoing success of the catalog, making it a continuously evolving and adaptive resource within the organization.