Metadata Augmentation#
Introduction#
Metadata augmentation is a process of adding metadata to the original metadata that comes with the data. The original metadata may have varying levels of metadata completeness. The set of augmentation methods implemented in this module aims to improve the metadata completeness of the original metadata.
We use automated methods to augment the metadata. The methods rely on AI and NLP techniques. The techniques currently include: language models (LLMs), vector embedding, clustering, and self-consistent prompting.
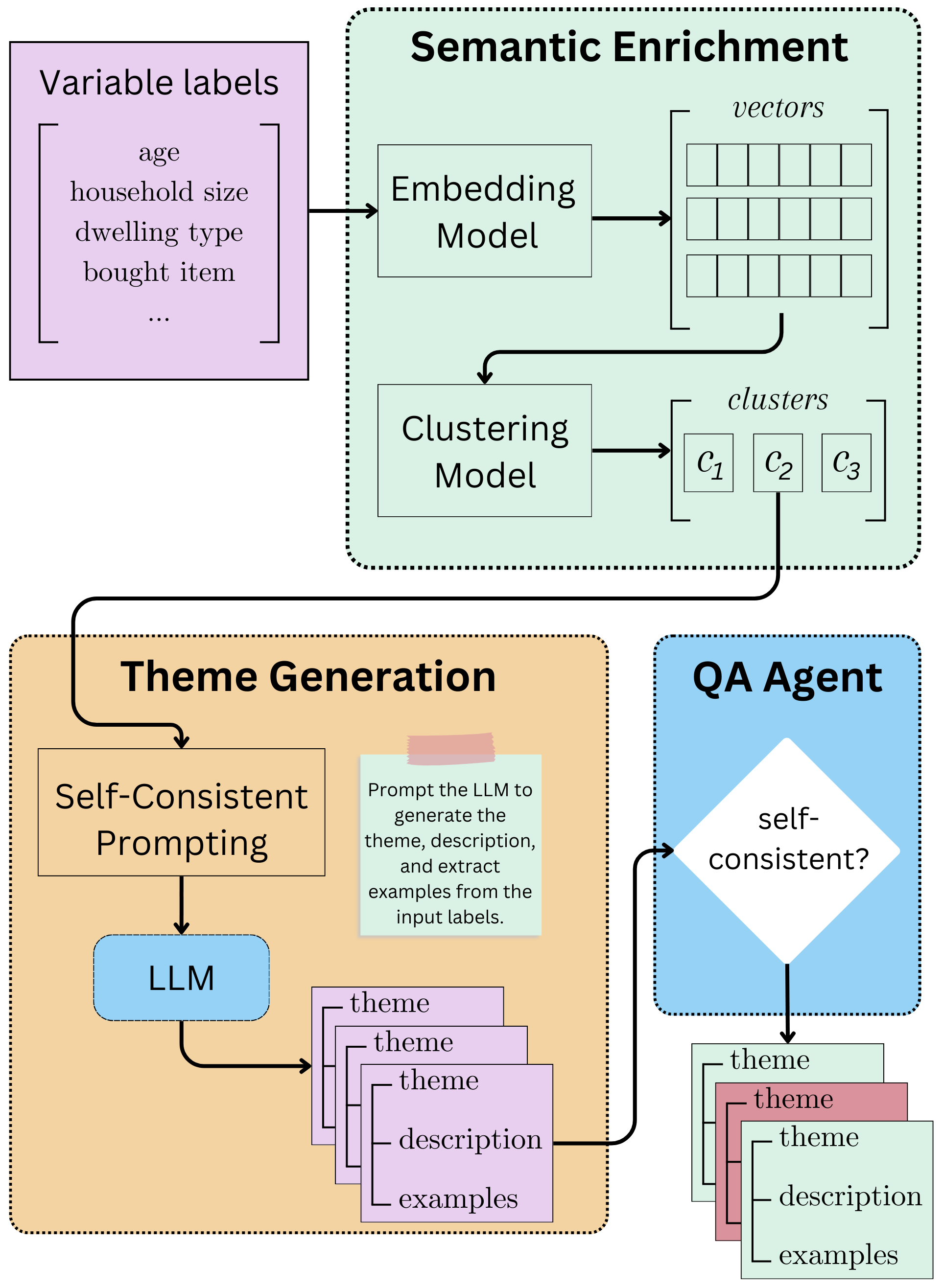
Below is a diagram of the theme generation process:
Methods#
1. Metadata Augmentation for Microdata#
1.1. Automated theme generation#
We implement an LLM-powered theme generation method to generate themes for microdata. The method is based on the assumption that variable labels and descriptions that accompany the microdata can be used to generate themes for the microdata. The method is implemented in the llm4data.augmentation.microdata.theme_llm module.
The method is based on the following steps:
Extract variable labels and descriptions from the microdata.
Cluster the variable labels and descriptions using an embedding model and a clustering model.
For each cluster, generate theme(s) using the LLM model.
Utilize self-consistent prompting and LLM-agent QA to automate the process of reducing the likelihood of generating themes that are not relevant to the microdata.
The generated themes can then be validated by human experts before the final themes are selected for the microdata.
Example
For a given idno from the microdata library, the method can be used as follows:
from llm4data.augmentation.microdata.theme_llm import ThemeLLM
theme_llm = ThemeLLM(
idno=idno,
llm_model_id=<llm_model_id>, # Defaults to gpt-3.5-turbo
catalog_url=<catalog_url>, # Defaults to https://microdata.worldbank.org/index.php/api/catalog/
)
# Generate themes
microdata_themes = theme_llm.get_processed_themes()